Steering Agile Architecture by Example: the Feature Toggles From Open edX
How do you keep documentation in sync with the code? How do you steer agile architecture? And how do you do that without reading code?
The magic answer: Moldable Development.
Moldable Development is based on a simple idea: software problems are highly contextual and are best dealt with through custom tools. It's a simple idea that is difficult to communicate because its value can only be demonstrated for a specific context. In a way, it's not unlike testing. Testing works not because a tool is generically applicable out of the box, but because we create tests specifically for each functional case. So, testing can be evaluated based on examples of domains that must first be understood.
Consider how we could convince people that we can steer the architecture of systems through custom queries and visualizations created specifically for each architectural concern. For this, we would need to first identify one or more such concerns and then go with the audience through the process of discovery guided by custom tools. In this post we do exactly that. We take a concrete system, Open edX, and we explore the architectural concerns around feature toggles.
Let's go.
Encountering Open edX
openEdx is an exciting system, used by many and developed in the open together with an active community. John Brant and I got to learn about openEdx while participating at a two-day hackathon. It was the topic of the hackathon that drew our attention: Love for Docs.
Indeed, we find this to be a fascinating topic. The docs is one of the important sources of information when we encounter a new project. Ah, I know what you're thinking: read the docs?! Yes. But, we don't read documentation to learn about the system. We look at the docs to learn what people think about the system. We'll get back to this point a little later.
We know that docs don't have a great reputation though which was even more of an incentive to take a look at a project that declares its love for docs.
Searching for an Entry Point
When we first approach a system, we need to get acquainted, to get a sense of orientation. We read code superficially. We skim through the docs .We chat with people (take a look at the Object-Oriented Reengineering Patterns book for inspiration). And we guide it all through analyses.
For example, we already knew that the server side of Open edX is written in Python. By mapping top folders containing py files, we learnt there a few top components. Here is how that looks like in Glamorous Toolkit.
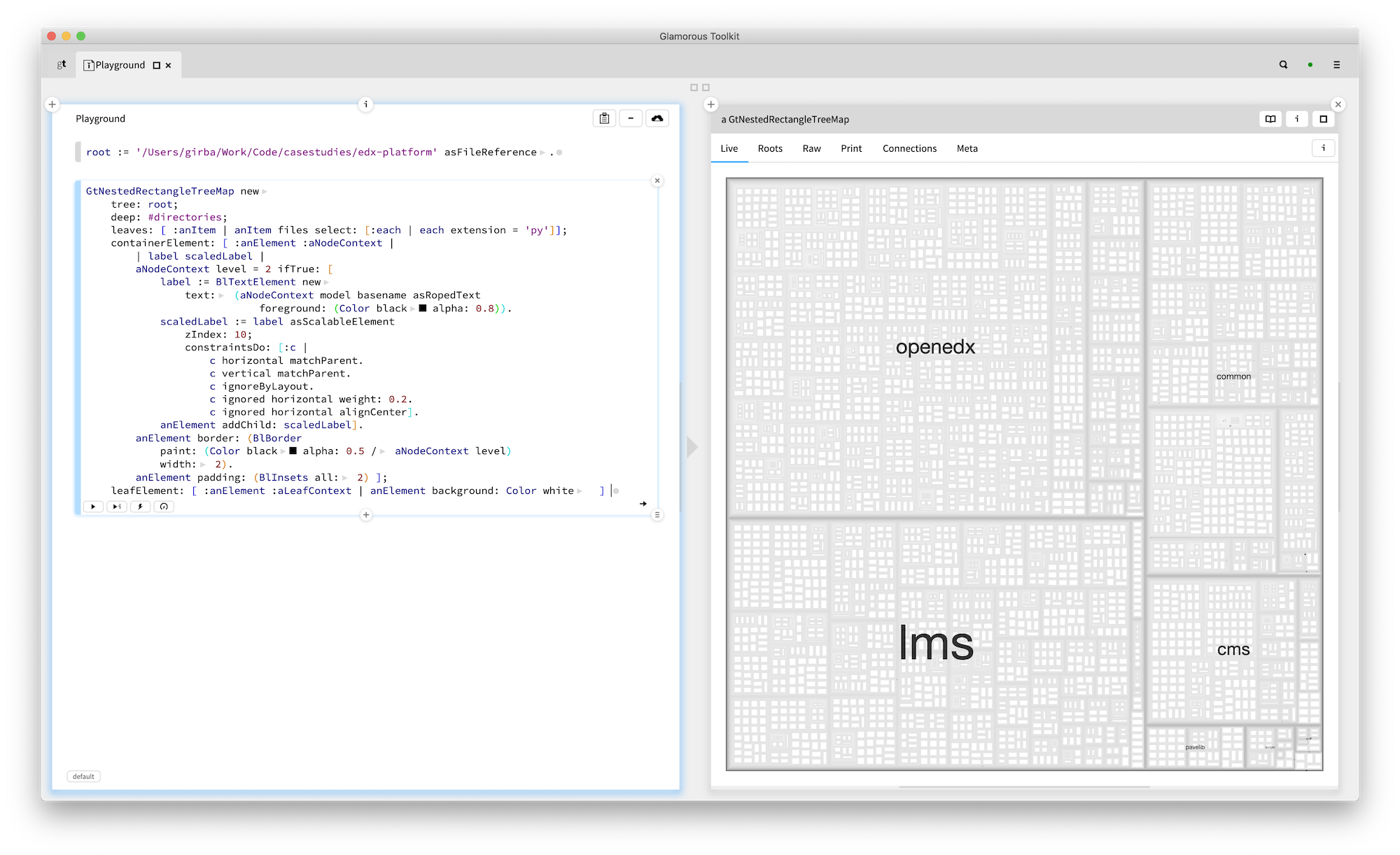
This is all nice and entertaining, but the goal of the search is to find an entry point: a problem interesting enough for the team that can be evaluated against the system. The code alone rarely points us to problems. The context around it is richer. We can learn about this context from people or documentation artifacts.
The volume of documentation from openEdx is significant. It covers all sorts of things. Particularly interesting for our purpose were the Open edX Proposals, a collection of resources that document decisions being made by the Open edX community. This is a treasure trove.
Architectural Concerns about Feature Toggles
Concern: Finding Legacy Toggles
One of the concerns that atracted our attention was about feature toggles. The documentation describes thorougly the intent of the toggle mechanism, the different flavors, the migration intention from the "legacy" toggles to the new form, and even provides a guideline for how to document toggles.
Remember when we said we like reading documentation? Here is why. When something is documented, we now know that this is important enough for the team to spend that effort. And when we see the documentation of a decision, we also get a glimpse into the intent of the team.
We decided to focus on this area. We also talked with developers. Robert Raposa was particularly helpful with providing examples and clarifying our misunderstandings. Oh, yes. There always are misunderstandings. The goal is to build a mental model that resembles reality as much as possible. Along the way, we'll formulate hypotheses, many of which will be wrong. Knowing this, we favor maximizing the amount of hypotheses we go through in a given time. And we'll get feedback from wherever we can.
So, let's take a look at some of the concerns we identified and evaluated through tools.
The first thing we can look for are statements that make a clear statement. For example, the decision document mandates that legacy flags should be migrated to newer formats. This is a direct statement that can and should be verified against code.
Here it is: all files containing a reference to a legacy toggle highlighted in the overall structure treemap.
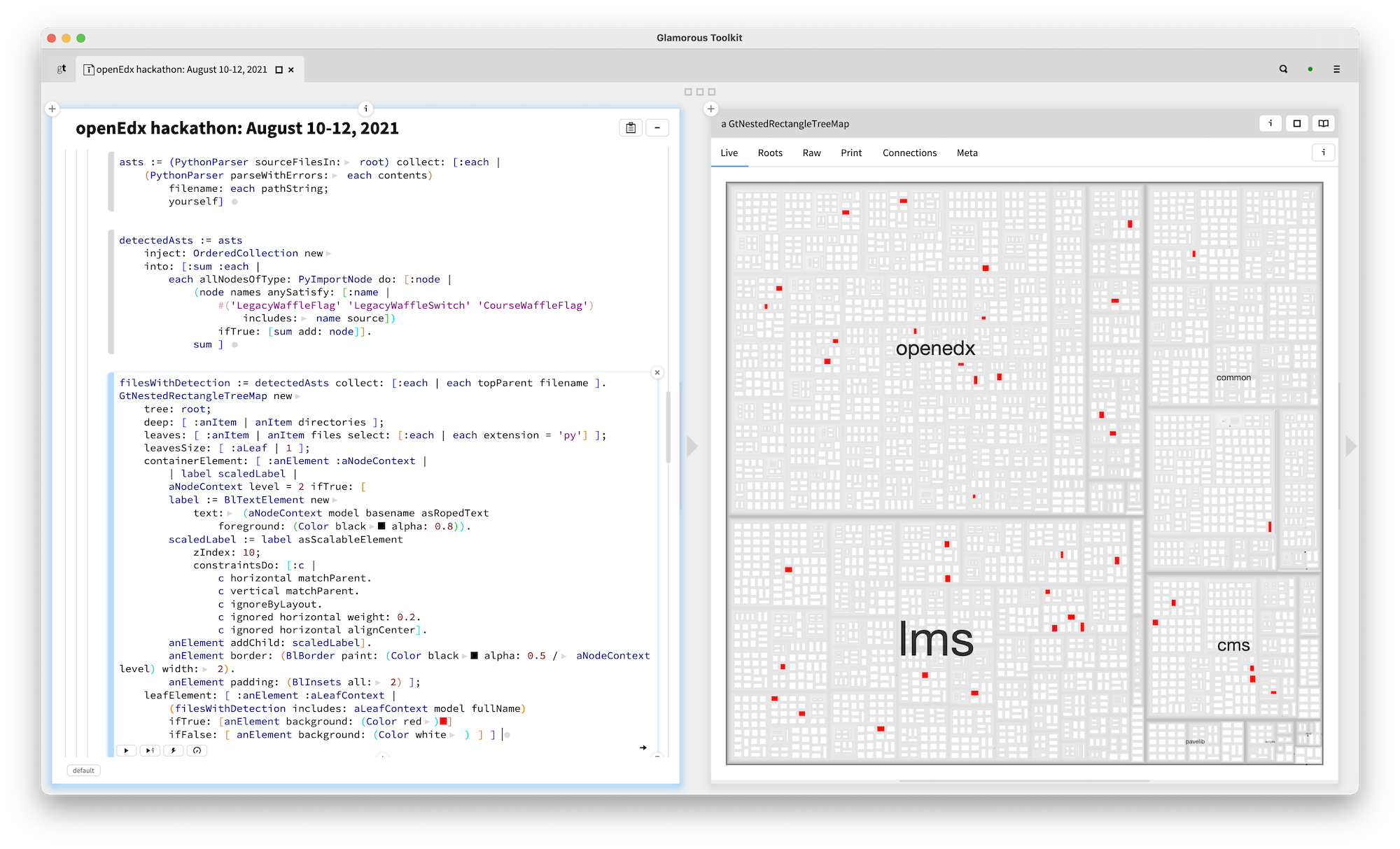
A query like this requires detailed parsing abilities. Indeed, Glamorous Toolkit ships with a Python parser. For example, here is how we produce abstract syntax trees (ASTs) for every file in a root folder. (If you want to try this at home, initialize the root variable the root directory of edx-platform).
asts := (PythonParser sourceFilesIn: root) collect: [:each | (PythonParser parseWithErrors: each contents) filename: each pathString; yourself]
Once we have the abstract syntax trees, we can directly detect those that import the legacy toggle classes:
detectedAsts := asts
inject: OrderedCollection new
into: [:sum :each |
each allNodesOfType: PyImportNode do: [:node |
(node names anySatisfy: [:name |
#('LegacyWaffleFlag' 'LegacyWaffleSwitch' 'CourseWaffleFlag') includes: name source])
ifTrue: [sum add: node]].
sum ]
That's it.
Interestingly, we later also found a custom Pylint script built by the edx team that identifies the usages of toggles in different forms that accumulated over time, including these legacy ones. This script resides in a separate project and holds a dozen of custom made rules. Why is this interesting? Several reasons, but let's get back to that a little later.
Queries are great as they can be transformed into automatic checks and be integrated in the continuous integration. Still, queries can also offer exploratory support especially when combined with visualization. The map above offers an example. Mind you, that map is still generic. If we'd know more about the system we'd likely customize that map as well to extract more value. Every single problem we encounter is a chance to better explain the system.
I should also mention that the visualization is interactive, too. Clicking on one of the files opens an editor on that files.
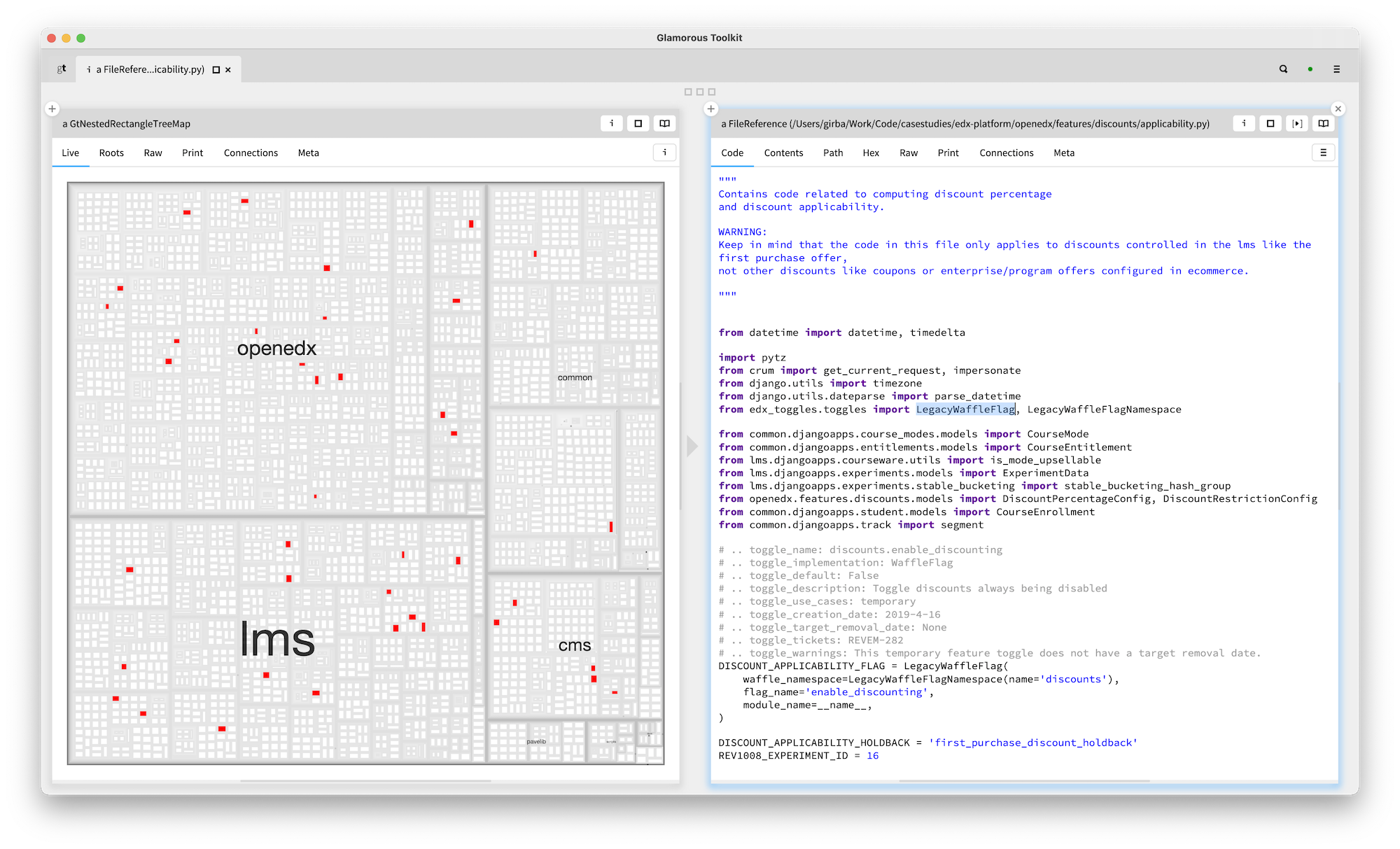
Let's ponder a little over what we've just seen. We identified a problem considered valuable by the team and captured it in a query. We did that in a notebook-like environment with debugging and quick inspection possibilities which lowers significantly the cost of creating the queries. And, when combined with visualizations, we get quick browsing options, too.
Compare this with the Pylint script mentioned above. From the end query perspective, the result can look similar. But, the key difference is in how the query was created. We created our query as a way to learn about the system while we were learning about the system. It was one of many, and this one just proved more useful than others. The outcome can look similar in this case, but the process is not. This behavior is possible because the cost of creating and evolving a query or a visualization is so low, often measured in minutes.
We maintain that every problem in software contains a data problem that should be explored through such custom tools, and without reading (much) code. When practicing Moldable Development, we create multiple such tools on a daily basis. At the same time, the edx-lint project that holds the said Pylint: at the time of writing, it shows that it was last touched over 5 months ago. When the cost of tools drops, new behaviors are enabled.
Ok, ok. But, do we really need so many queries and visualizations? Yes. Read more to learn why.
Concern: Undocumented Toggles
Towards the end of the hackathon, someone asked what can he do in a few hours, and was proposed to pick undocumented toggles and ... well, document them. Sounds easy, right? Well, how do you find the undocumented toggles? I asked that very question in the chat and Robert promptly offered to put together a list based on an internal tool they have if only I'd like to document some (I must emphasize again that Robert did a wonderful job during the hackathon and he kindly put up with all my odd questions). I did not want to document the toggles, but that answer alone was interesting enough to prompt my interest for two reasons.
First, if someone looks for something in the system, that's a cry for some custom tool. Second, indeed, a tool does appear to exist, but it is not entirely trivial to get results out of it. Tools must be inexpensive and available. Given the amount of time spent on retrieving information from the system, ensuring the infrastructure for such tools is at least as important an architecture decision as any other major decision. Also, a tool for a specific query should not be an easily recognizable standalone tool. If it is, you likely have way too few tools.
Back to our problem. The documentation mandates that toggles should be annotated with textual descriptions and provides ample examples of how. This is great. Now, to identify the undocumented toggles, we first need to identify all toggles. And then we need to find the associated documentation, too. Which is what we decided to do.
This is where the analysis effort gets a little more elaborate. In this case, too, we found another Pylint script that detects whether feature toggles are properly annotated. This script is rather laborious. We approach problems like these slightly differently: we introduce an intermediary step of constructing a model. As there are multiple mechanisms for defining a toggle, the dedicated logic does not fit comfortably in a single script. And, we eventually also want to get a toggle definition modelled as a first class entity that we can query, too. When we hit such situations we introduce a model.
For those interested in implementation details, I invite you to follow the instructions at the end of this article. In the meantime, here is an outcome.
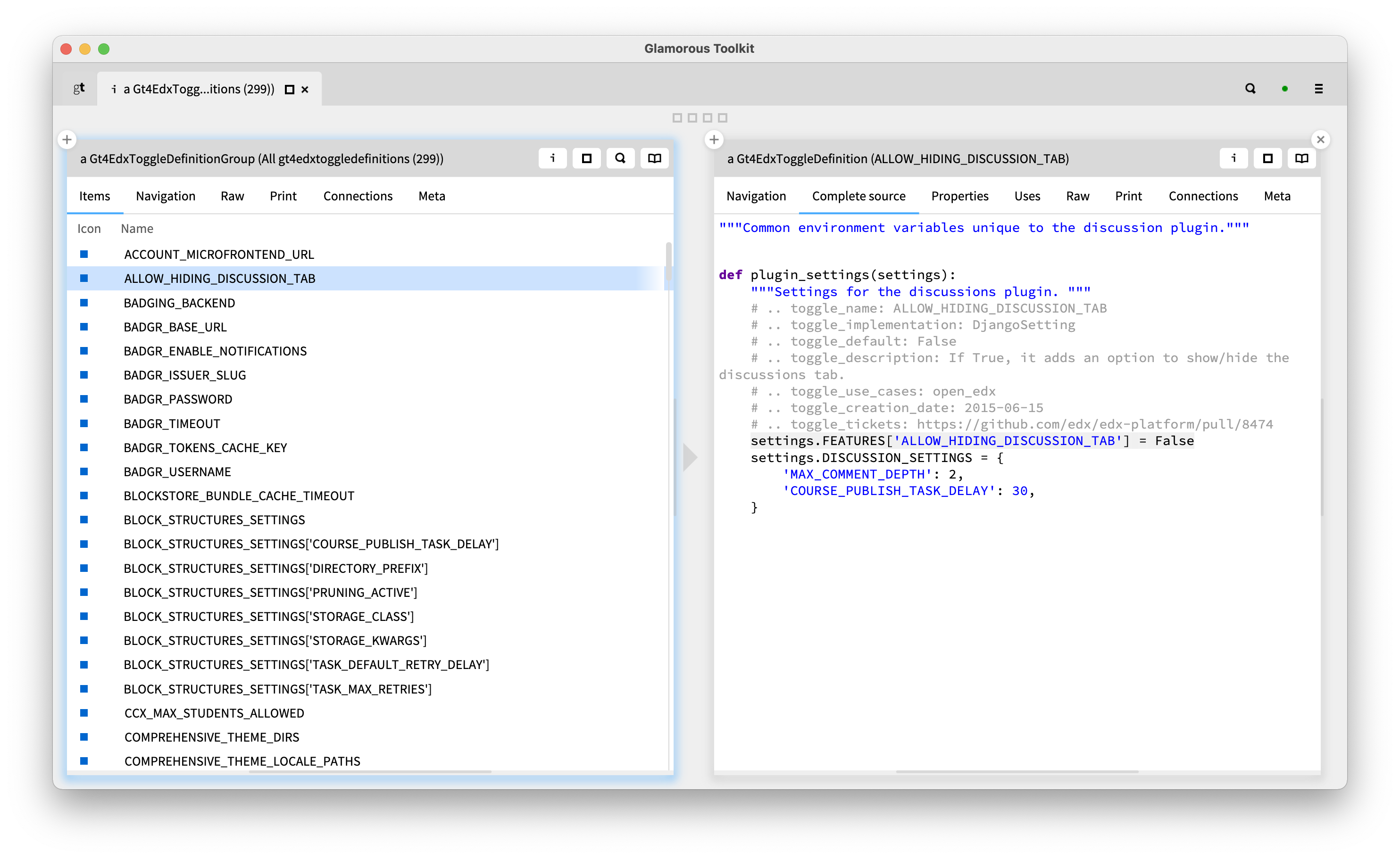
On the left we see 299 toggle definitions detected statically. On the right, we see the source code associated with one such toggle. We validated the list of toggles against the list published by the openEdx team which at the time of writing contains only 225 entries, all of which are detected by our solution. We detect more toggles also because we are able to detect statically toggles that have no comments.
With our importing logic, beside knowing the location in the source code, a toggle definition object also knows the comments associated with it. So, finding out which toggles don't have any comments is a matter of a simple query. We see it below in the object playground from the first pane.
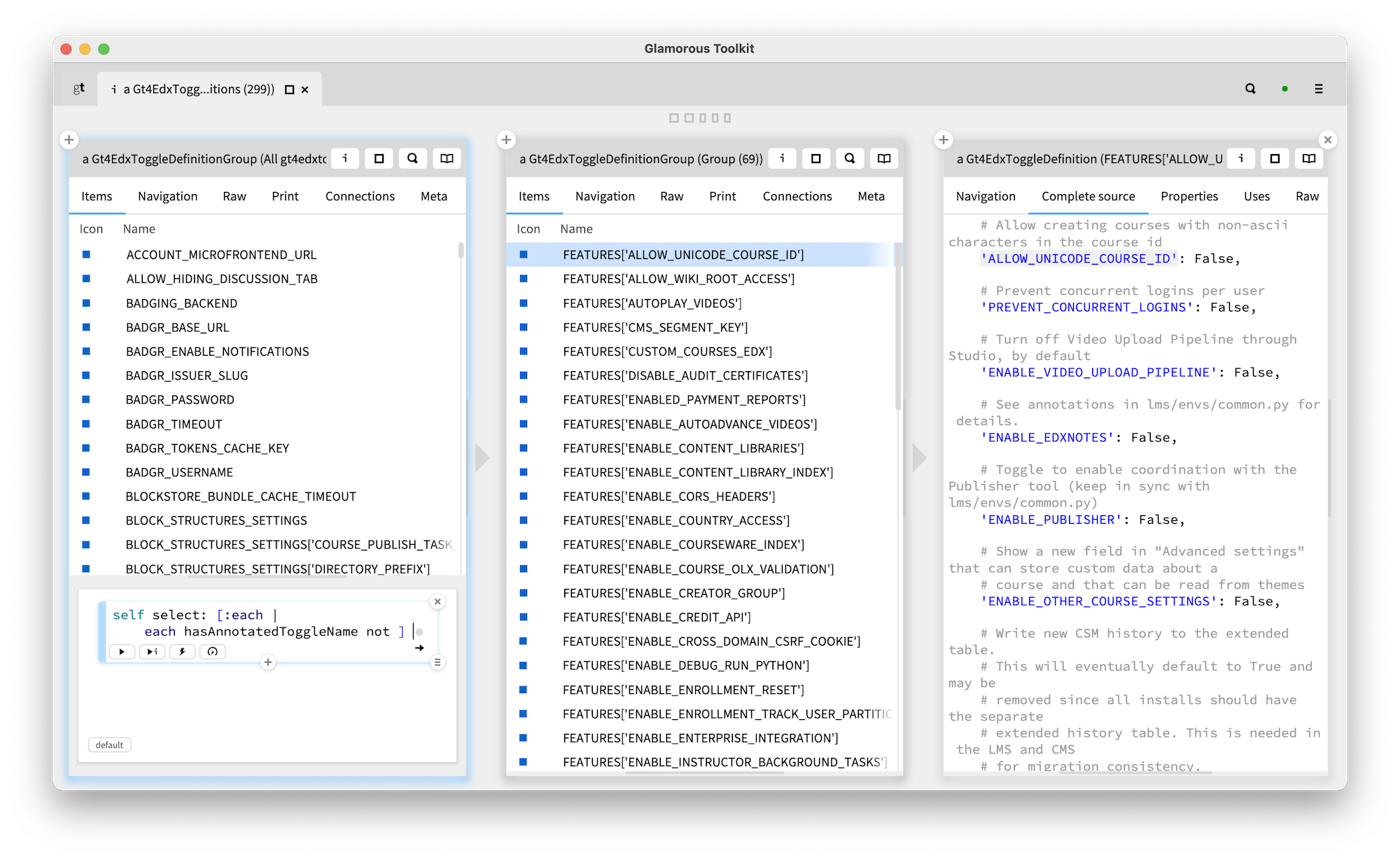
In the version of the code we looked at, we detected 69 instances of toggles without a name comment. Similarly, we can identify whether a comment contains the right kind of annotation, too.
The result itself is secondary for the purpose of this work. The main target is to show that it is possible to go in a short amount of time deep into a specific problem of a system about which we previously did not have any knowledge, and that we can do that without reading code.
In the previous section, we talked about how the interactive nature of Glamorous Toolkit lends itself nicely to supporting exploratory browsing. We see this ability at play here, too. We write and refine queries in the same environment in which we are viewing the system, too. This allows us to have a conversation with the system through which we systematically refine our hypotheses. This is a never ending, yet ever refining process. It's an infinite game that should last as long as the system does.
Concern: Wrongly Documented Toggles
Once we bootstrap a model, we can start asking further questions at low costs. For example, we noticed that the name of a toggle appears twice: once in the comment, and once in the name of the variable. This then begs the question: are there toggles that are named differently in the code and in the comments?
We detected one.
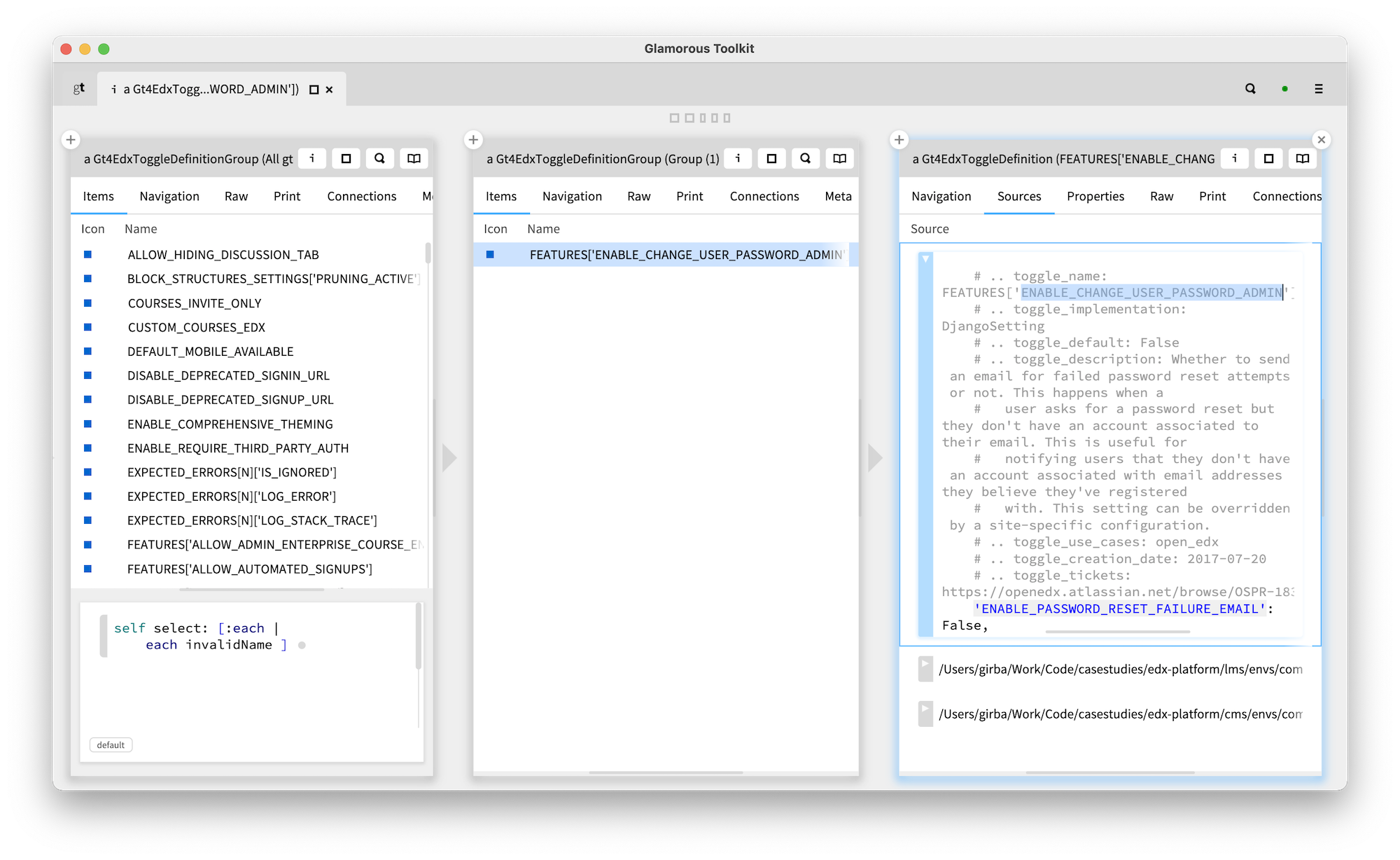
Why would this be relevant? Well, the openEdx project offers a list of all known toggles online. This list is put together based on the comments alone. At the time of writing, the actual property from the system does not appear in the list because the comment is wrong. In fact, the comment label is duplicated in the same file (see it inthe edx-platform GitHub repository).
This query was trivial once we had a model. We did not detect many, but the fact that there is one problem when it's so straightforward to fix only shows how easy it is to get to inconsistencies when the desired properties are not captured as constraints.
Concern: Toggle Usages
Constructing a model has compounding effects: every new entity and connection adds super linearly to the expressivity power of our model. In our case, next to toggle definitions, we also captured the toggle usages. Here is an example of a toggle definition on the left, the list of its uses in the middle and the source of a specific use on the right.
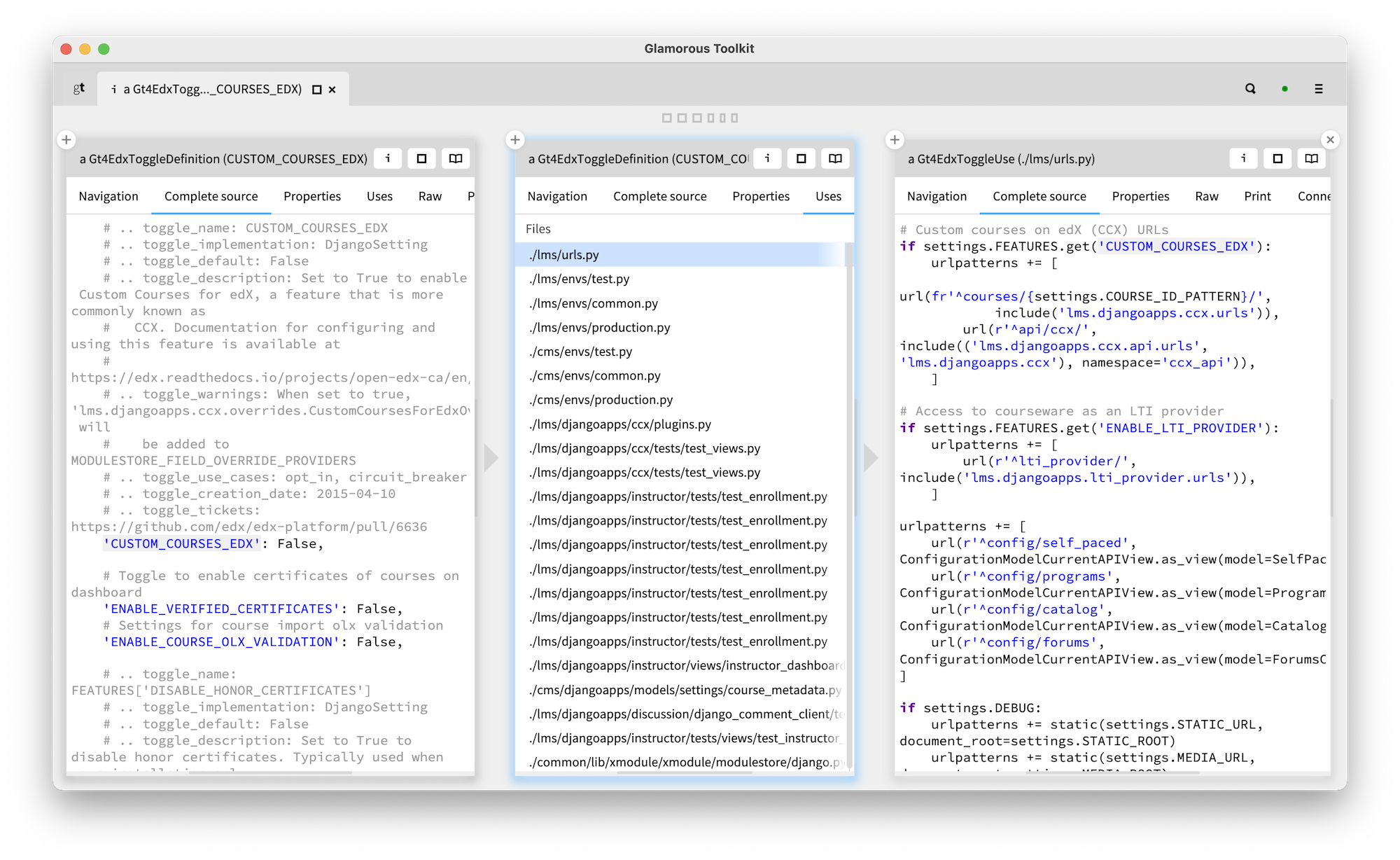
It gets even more interesting when we consider that a use of a toggle essentially adds a dependency to the place that defines the toggle. And if we aggregate this information at the level of components (in this case, we picked the top level directories as course grained components), we get something like this:
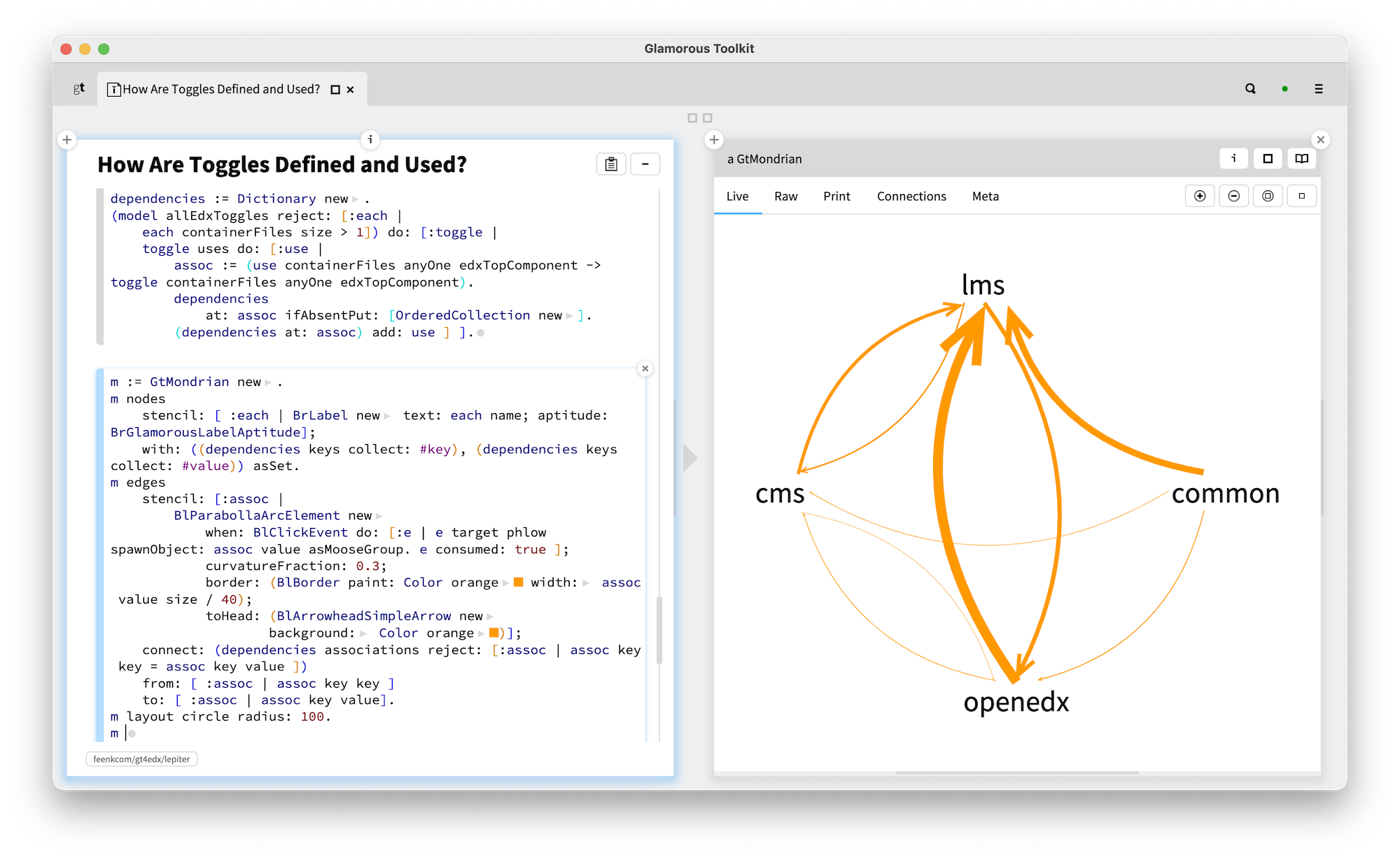
This dependency is not detectable when we look at the system from the base language perspective. Take a look below. On the right we see one of the toggles defined in the lms part that is used in common. The use is based on looking up a string. From the language's perspective that string is a string like any other. But, from the toggles framework's perspective, this string has a special meaning.
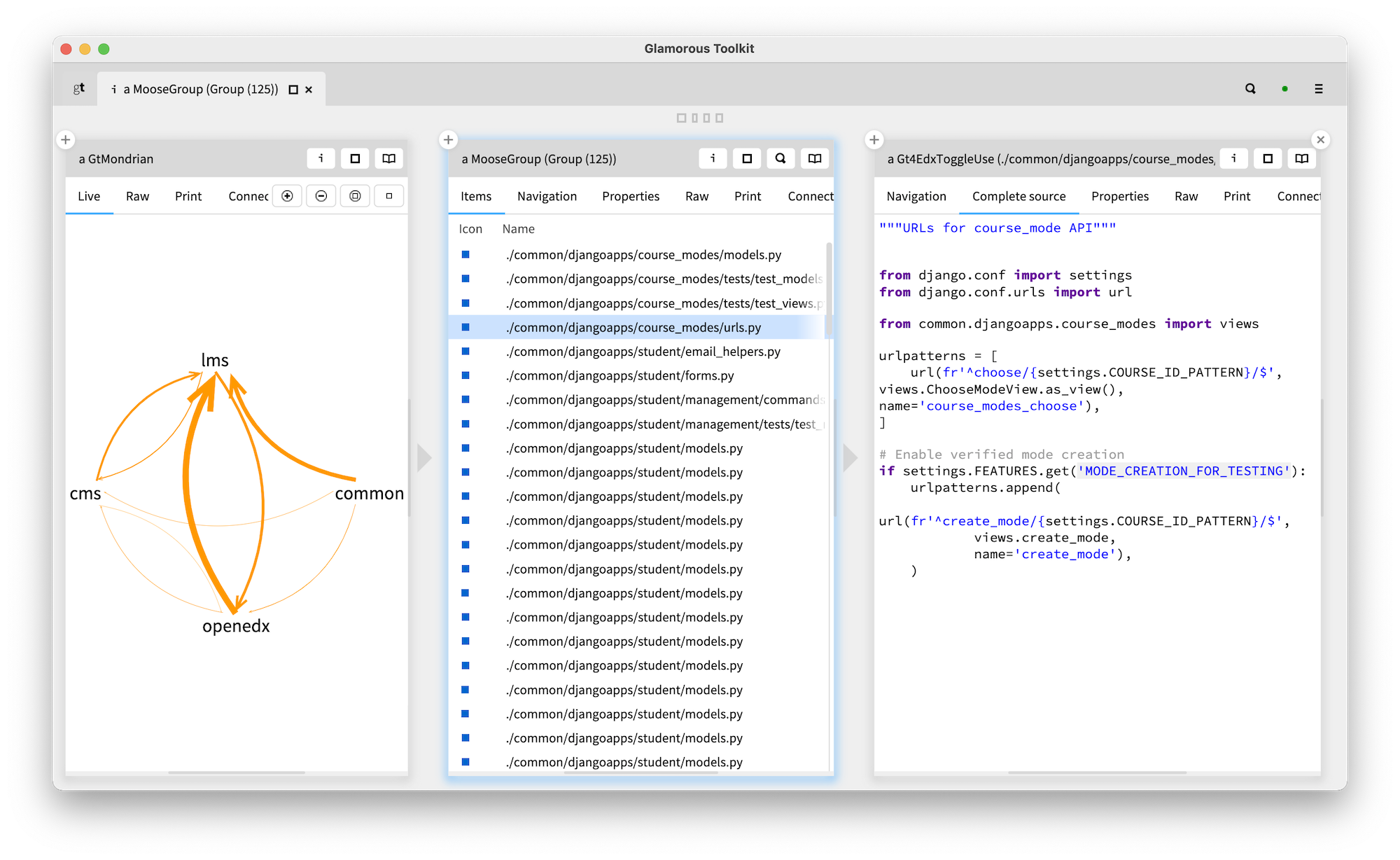
This excersie shows that without a view like this, the dependencies introduced by toggle usages would be invisible. We need tools, but because software is highly contextual, tools must take that context into account to be meaningful.
Bonus: Live Documenting a Concern
One more thing. What if documentation was an active tutor?
For example, here we see a textual description of the legacy toggles concern on the left, while on the right we get two editors. The editors are live and allow one to play. And, hovering over the text on the left provides visual links into the text.
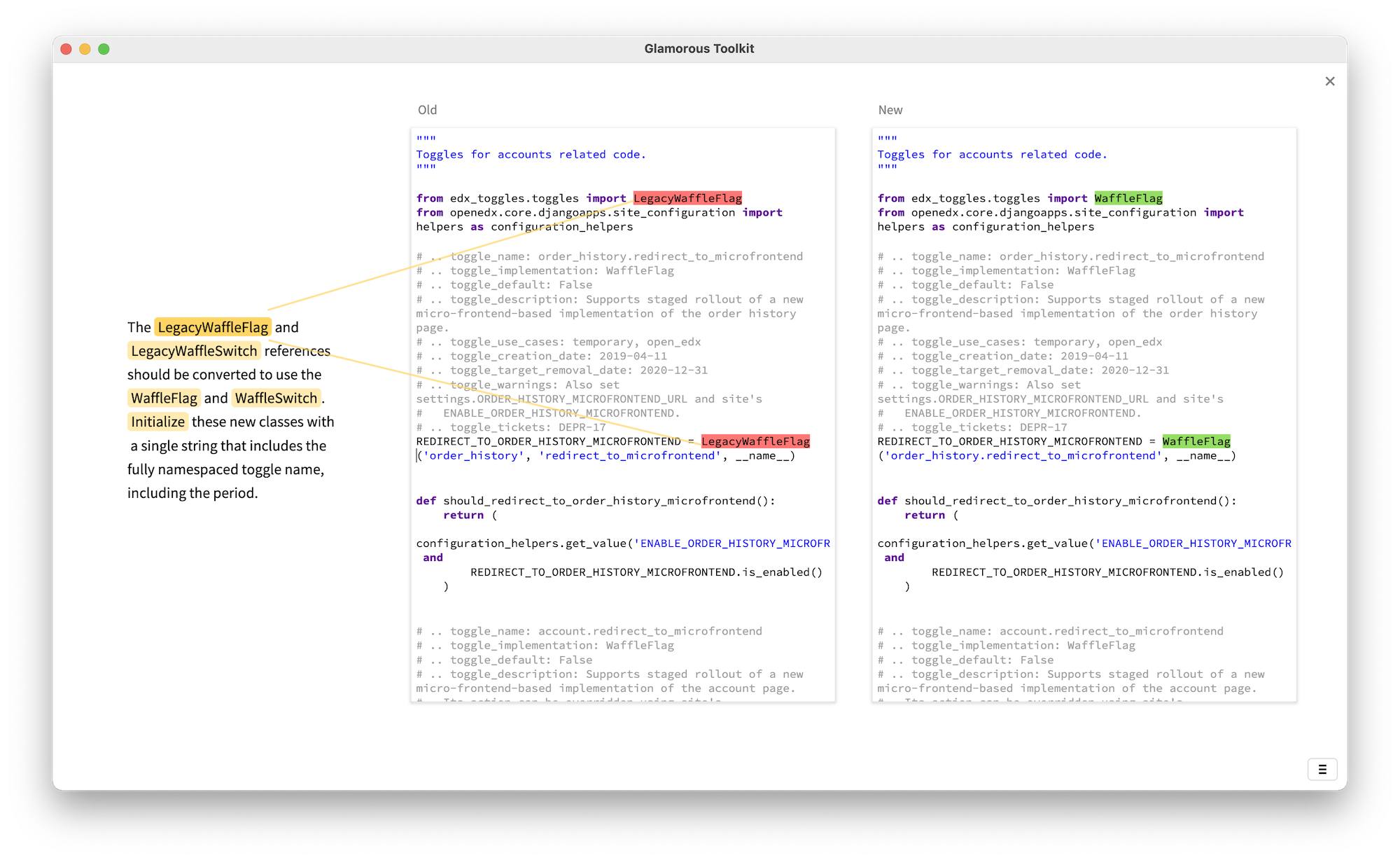
Consider the challenge of onboarding: developers need a systematic reference to get an understanding of the entire system. Documenting decisions does provide an interesting overview into the reasoning behind the system. However, if the documentation is live, it can also act as a tutor for newcomers.
What Does It All Mean?
We managed to cover quite some territory in a short amount of time. We identified a recognized problem, we split it into multiple detectable issues, we created the detections, we built ways to browse the violations and we identified hidden dependencies. All these in a system and technology previouisly unknown to us. We managed to do all this because we actually did not read (much) code.
Documenting decisions in textual ways is great, but we can add much greater value by backing up those decisions through custom tools that help us steer the architecture for the long run. The system did have some tools, which is good. But, there are only few and don't go as far as they could.
Over the course of this project we created dozens of queries and a number of visualizations. We also distilled our understanding in a model. We could do this because the cost was low. In fact, this is one of the main messages we want to transmit: the cost of creating custom tools is essential. In our case, we could do all this because of Glamorous Toolkit.
Perhaps you draw the conclusion that Glamorous Toolkit is cool. I won't disagree with you. Still, if I could choose, I would prefer you to simply acknowledge that it is possible to reason quickly about your system, that it is possible to document and communicate about your system in a maintainable fashion, and that you can actively steer your system.
So much of today's software engineering energy is spent on reading and manually extracting information from the mountain of ever changing system data. Custom tools can automate a large part of this energy which means that we, as engineers, can get free to think together with our systems as the systems change. There are so many implications when this happens.
With Glamorous Toolkit we show that the theory of Moldable Development is practical. The cost of custom tools can be much lower than people think. So, now that you know it's possible you can go look for how you can apply this thinking in your system.
One question is how you should go about introducing Moldable Development in your team. Every time we replace manual work with automation, the real benefits are extracted when we rethink the activity as a whole. In this case, the activity to rethink is software engineering, and more specifically the way we can equip ourselves to steer our systems. Adding a new tool will have a marginal impact. If you want to extract the actual value, you need to adopt the skills associated with Moldable Development and change your processes, too.
Adopting Moldable Development: a Primer
Moldable Development is focused on facilitating technical decisions. It starts with a hypothesis that is evaluated through an analysis. If we are confident in our interpretation of the results, we act. This is not new: it's merely the scientific method. The specific addition is the question of whether there exists an appropriate analysis for the hypothesis in the first place. This is a key question because if the tool is missing, people end up reading, which is the most manual way to extract information out of data. So, what do we do when the analysis is not available? We mold it.
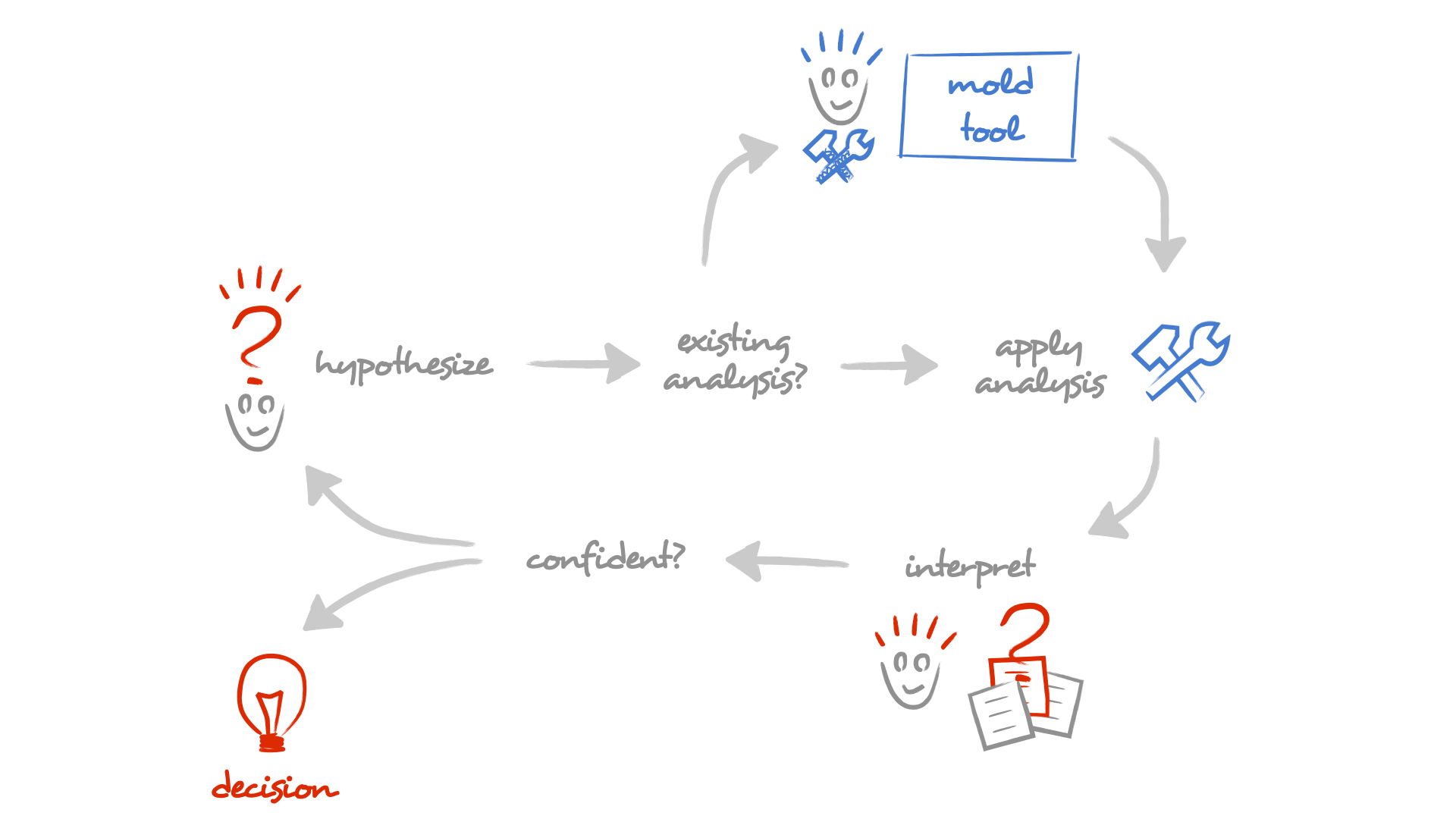
There are two interesiting roles: the stakeholder formulates the question and knows what to do with the results; the facilitator facilitates the exploration by creating custom tools.
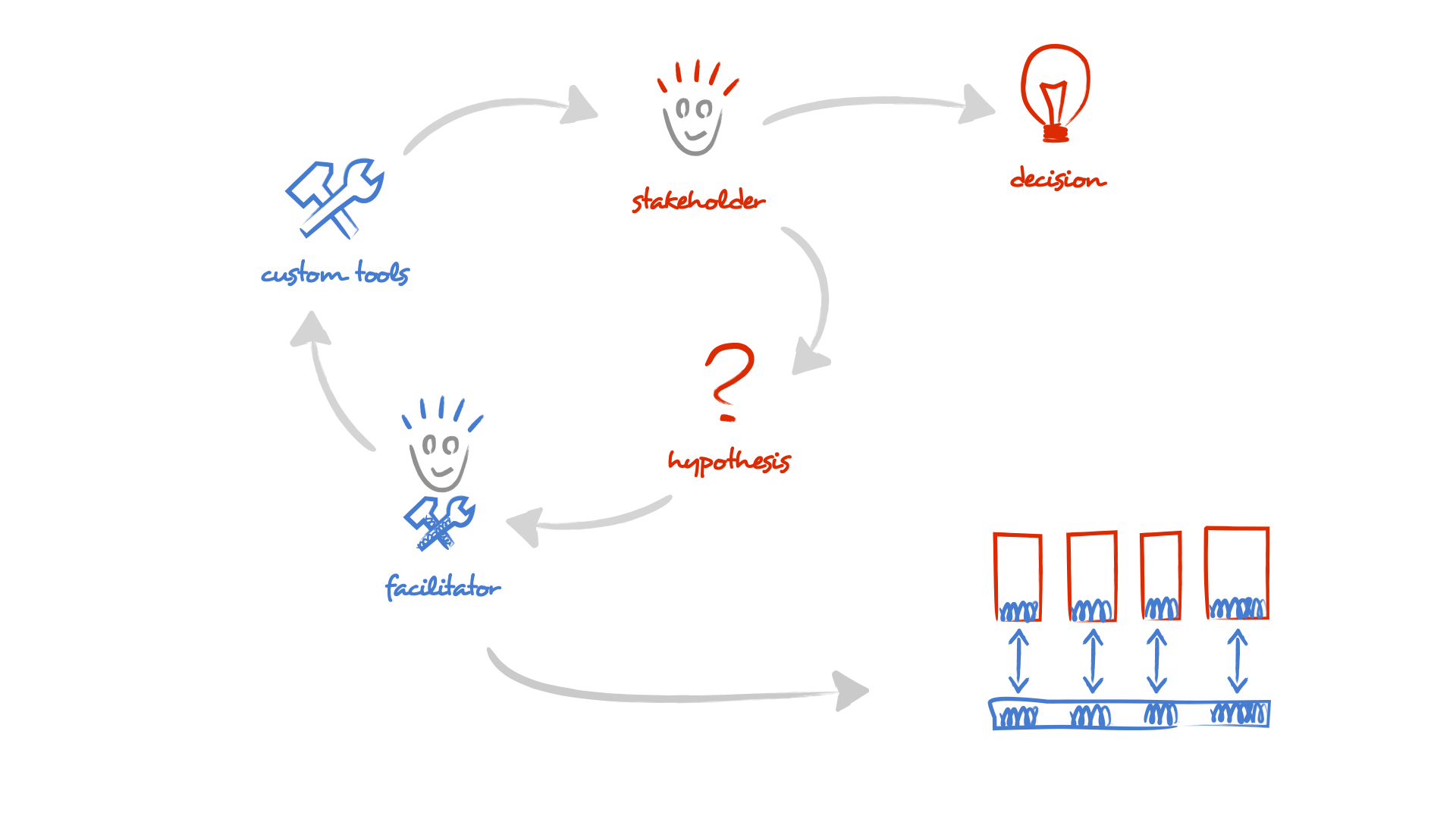
The facilitator is a technical role, and can be trained similarly to how you train any other technological ability. In our experience, within a team of 8-10 people, there typically exists one member that is inclined to tinker with tools. That's often a good candidate, and 1 facilitator in 10 person team is a good ratio to start from. It is essential to have a facilitator in the team because the creation of the tools must be immediately available.
Still, the determinant role is the stakeholder. Everyone with an interest in the system should be a stakeholder. However, stopping and formulating explicit questions is distinct from today's typical development flow. This is also the hardest part to train.
In our exercise, we played both roles. This is not ideal, but it's what we typically do when we bootstrap a team to incorporate Moldable Development. It's not ideal because it is easy to fall into the trap of creating tools for the sake of tools. Tools should always be evaluated through how they influence decisions. The key input in our case came from the documentation and the brief developer interaction. It was because the toggle challenge and its importance were documented explicitly that we are more likely to have created value through tools. Even so, without incorporating this feedback into the daily work of the team, it's merely entertainment.
When the cost of documenting concerns is high, only course grained decisions tend to get documented and have a chance of being tracked. Instead, the goal is to bring this traceability and the involvement of the team for, ideally, every single decision, starting from the tiniest ones.
This leads us to the process side. Moldable Development can be utilized in multiple ways one of which is steering architecture. The starting point is that the only architecture that matters is the one that gets reflected into the system. Every commit influences the resulting architecture. From this perspective, you don't have a single architect and many doers. There are only many architects, and architecture is a commons. And a negotiation.
The daily assessment routine creates a space where this negotiation can happen explicitly. Anyone can raise a concern at any time about anything in the system. After the concern is captured in a checker, the detected places are brought to the attention of the team. I should stress that only concerns that are backed up by data from the system are relevant for this process. The conversation can be organized as a meeting, but it's important to have it strictly time boxed. The goal of the interaction is to reach a decision. To facilitate this, the concern should also come with a default action and have the rest of the team be able to veto it.
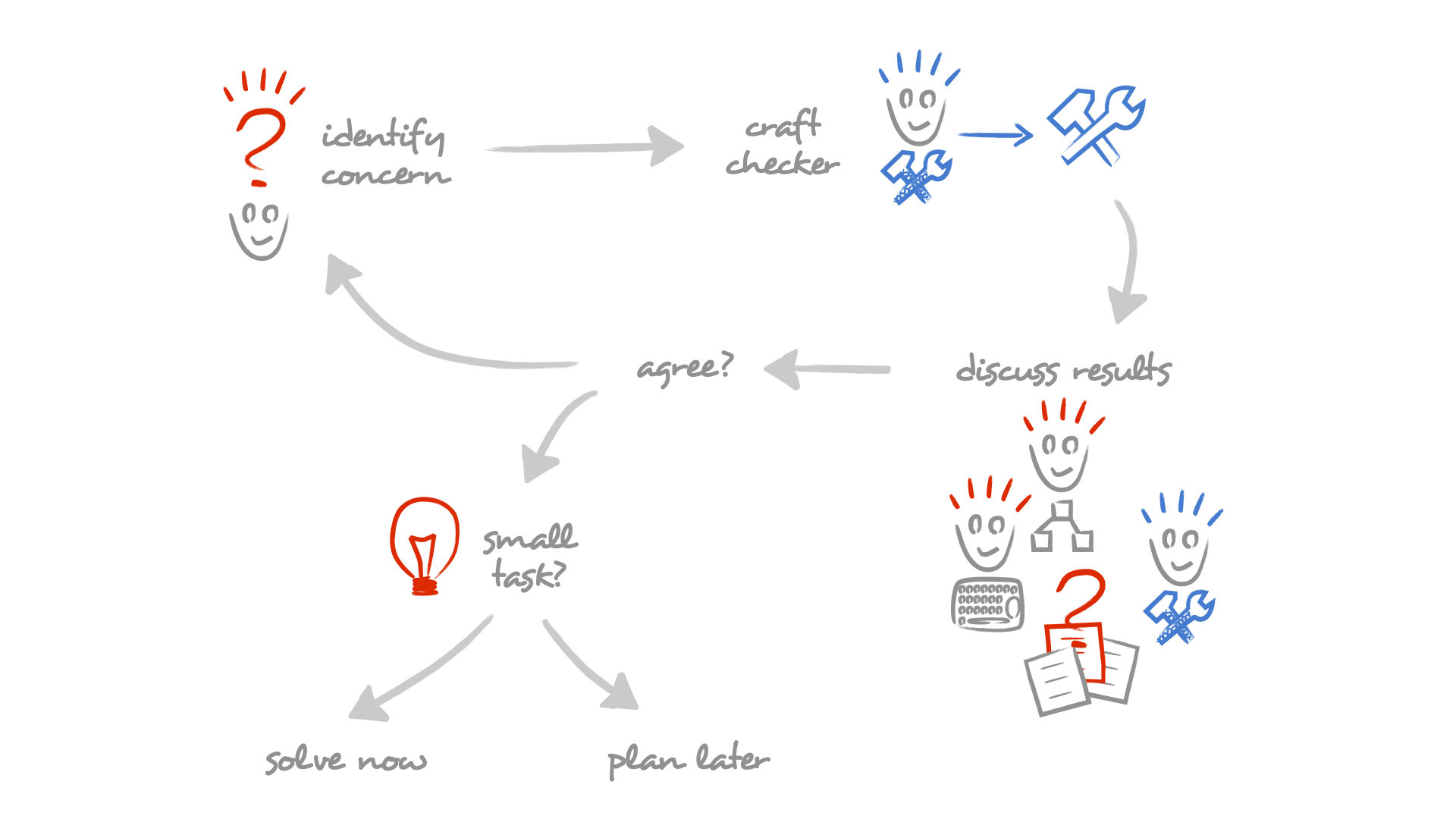
We typically advise people to aim for a 5-minute limit for a debate. We find that if a resolution cannot be found within that time, it's because the concern is not clear.
How can a resolution be found so quickly? You might be thinking of those long lasting architecture board meetings. The main reason why those last so long is because they leave room for what-ifs. When the same people are presented with concrete examples and the path forward, the conversation is typically much shorter.
At the end, the team follows through and fixes the problems, too. This happens in tiny increments and the whole process becomes a treadmill that can crunch through concerns. There are several side-effects. First, the knowledge gets spread in the team. Second, people learn that they can influence explicitly the course of the system. Third, the team establishes a systematic mechanism for dealing with technical concerns that is part of the normal routine and not a special event.
I mentioned that the stakeholders are the most difficult to train. But, the process facilitates the learning. At first, only few will raise concerns. As the others witness that a person can influence the team, they will have an incentive to do the same. The more concerns are captured, the more value the whole process creates. This is a positive feedback loop and it's the reason why the process can get sustainable.
How to Reproduce This Excercise
We documented our effort in a dedicated GitHub repository. If you are interested to reproduce the results please follow the instructions from there. The project comes with the code specific for the toggles importer and model, and it provides a live documentation that can be played inside Glamorous Toolkit as well.
If you do get so far as to try it, please consider sharing your experience with our community, or just let us know what you think about it.