Introducing Lepiter: Knowledge Management + Multi-language Notebooks + Moldable Development
More than a decade ago, we set out to make the inside of software systems explainable. We started from the observation that software engineering is primarily a decision making activity about lots of ever changing data points represented in code and other artifacts. We conjectured that tools are essential in this endeavor but for them to be effective they have to be adaptable to the context of each single development problem. They have to be moldable.
We are building Glamorous Toolkit to show how that can work in practice. Now, here is a secret. We do not do it to show others. We do it to show ourselves. We did not know how the environment would look like when we started. And we do not quite know how it will look in the future either.
Why? Because this is uncharted territory. The way we navigate this territory is by observing, formulating hypotheses and building experiments to evaluate them. One of these observations is that the I in IDE stands for integrated. It stands for integrated because development implies making multi faceted decisions that require many perspectives simultaneously. Yet, when we look at software development today we see a space of fragmented tools. Just consider how editors are often different from instrumentation tools which are different from API tools. Forming a multi faceted opinion becomes hard not necessarily because we cannot formulate it, but because we have to piece together the picture manually.
Another observation is that the integration must go well past the developer. Decisions need to be collective and informed, and the only way to reach that goal is to make the inside of the system explainable to the different stakeholders. Narratives play a crucial role in this. We need them to make sense of a situation. We need them to communicate with our peers. We need them to reach a consensus.
The hypothesis we put forward is that the primary job of the environment is to help us construct, consume and share many narratives with and about our systems. This led us to create a new kind of a development experience. We made every object be able to tell stories through custom views and actions. We made it possible for each object to know how to search itself. We made the debugger change its shape whenever there is an interesting event on the stack. We made the editor be able to adapt to the code we are writing. We bridge the gap between coding and documentation through examples (tests that return objects). We created live documents out of all these.
It worked. We learnt that true integration can be more than the sum of the parts. We found that when we change the nature of our tools, we also change the way we think about our systems. We change the way we think about our work, too.
And now, it's time for another leap.
When we say narratives, we might think of knowledge management. Or we might think of notebooks. Yet again, seamingly separate spaces. Well, here is a new hypothesis: they are not.
Enter Lepiter, a new moldable component in Glamorous Toolkit with which we unify knowledge management and programming in multilanguage notebooks.
A tour of Lepiter
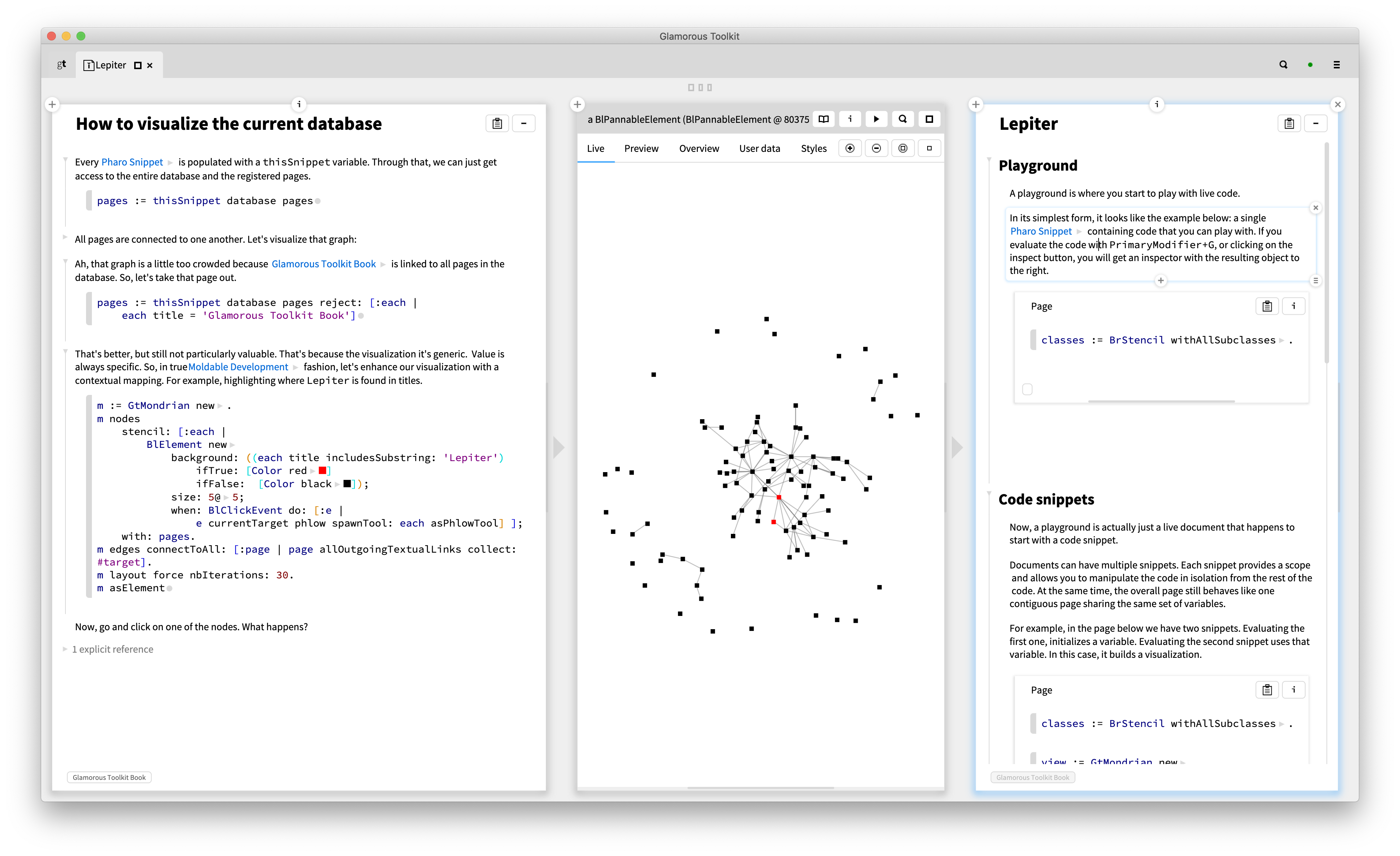
Lepiter is made of snippets assembled in pages. Each snippet has its own language and comes with its own editor. In its simplest form, it's a Markdown note taker with live markup that appears on demand and with expandable links.
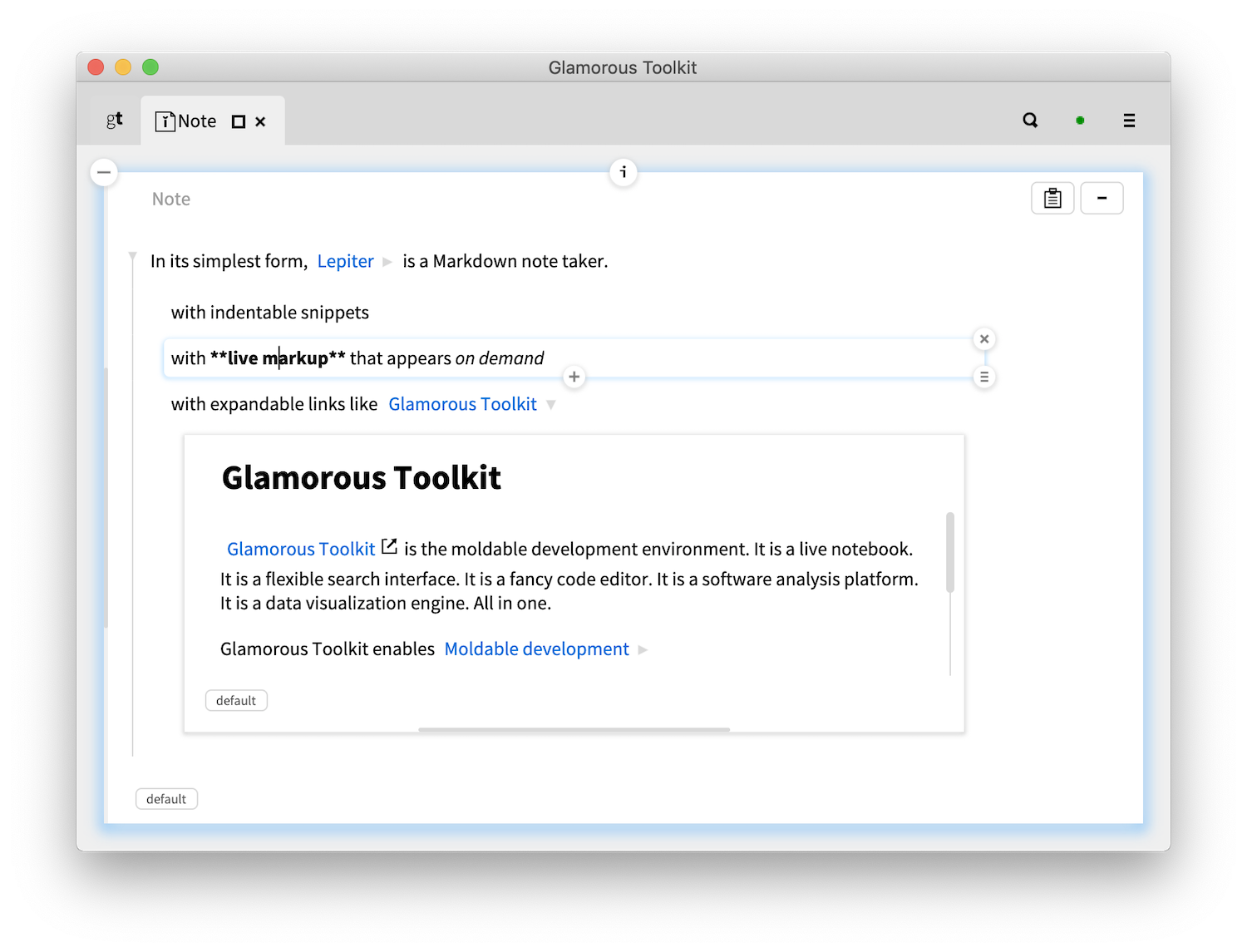
Pages reside in a knowledge base. And when we combine them with a table of contents, pages can form a book. We now ship such a book to document Glamorous Toolkit itself.
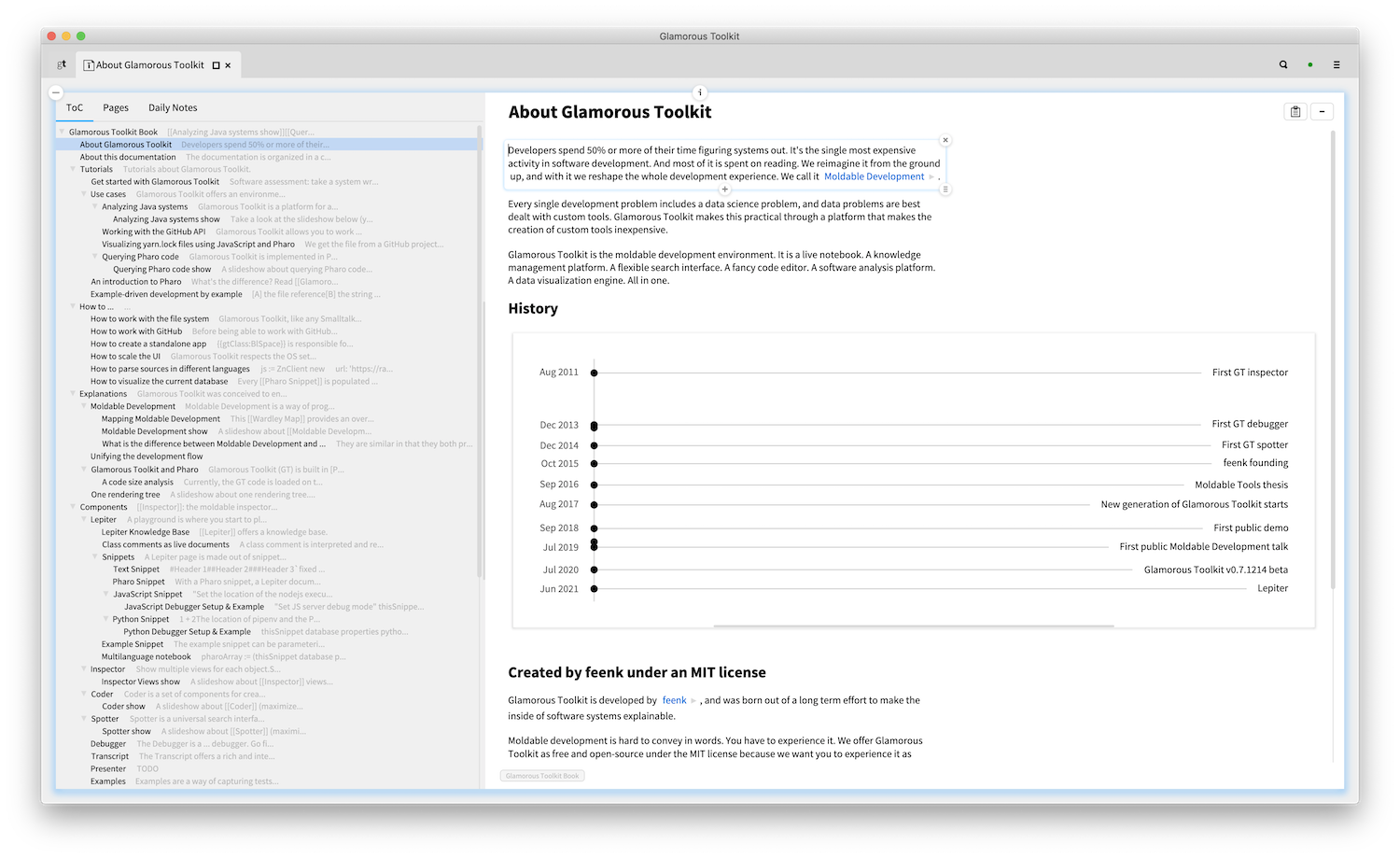
In the spirit of moldable development, the knowledge platform is also moldable in several ways. First, changing the snippets can change the utility. For example, a Playground is but a page that starts with a code snippet. Here, you see a page on the left with Pharo code, and an inspector on the result on the right. Let's get back to this a little later.
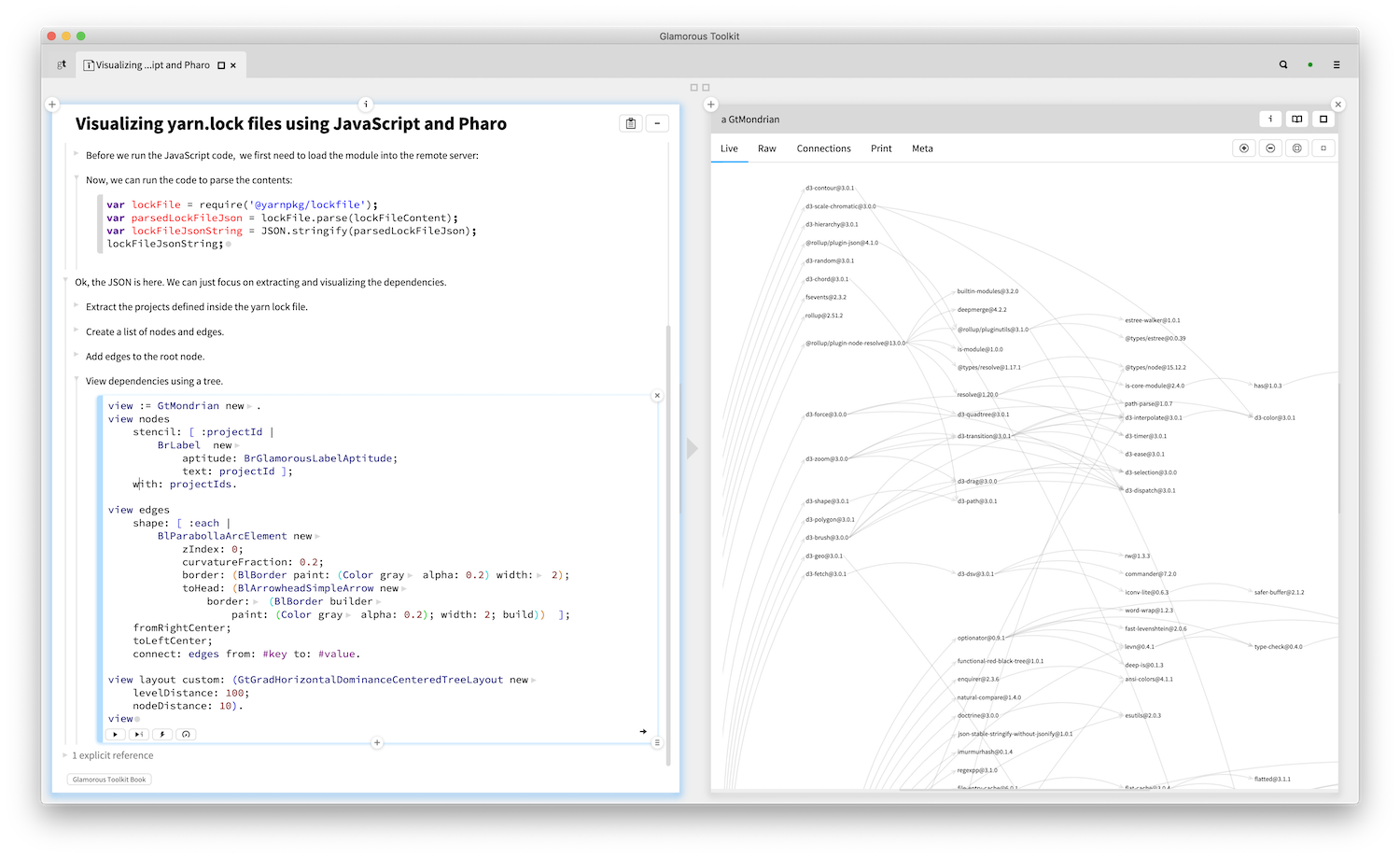
The example above shows Pharo code, however a code snippet is not limited to Pharo. Lepiter ships with snippets for running JavaScript (through NodeJS) and Python. And, you can mix and match, too. For example, here we have a page that mixes Pharo and JavaScript code to visualize dependencies defined in a yarn file.
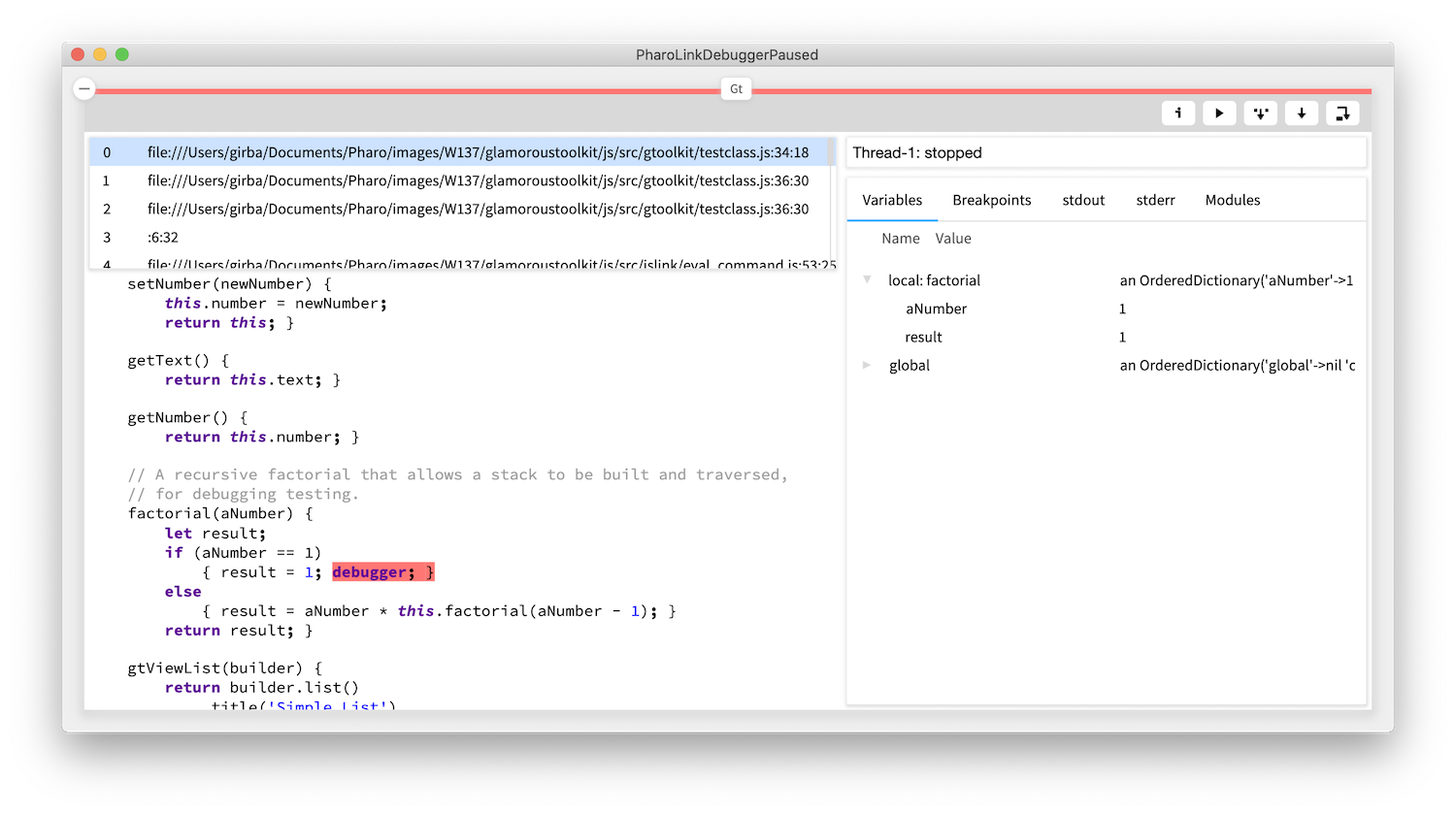
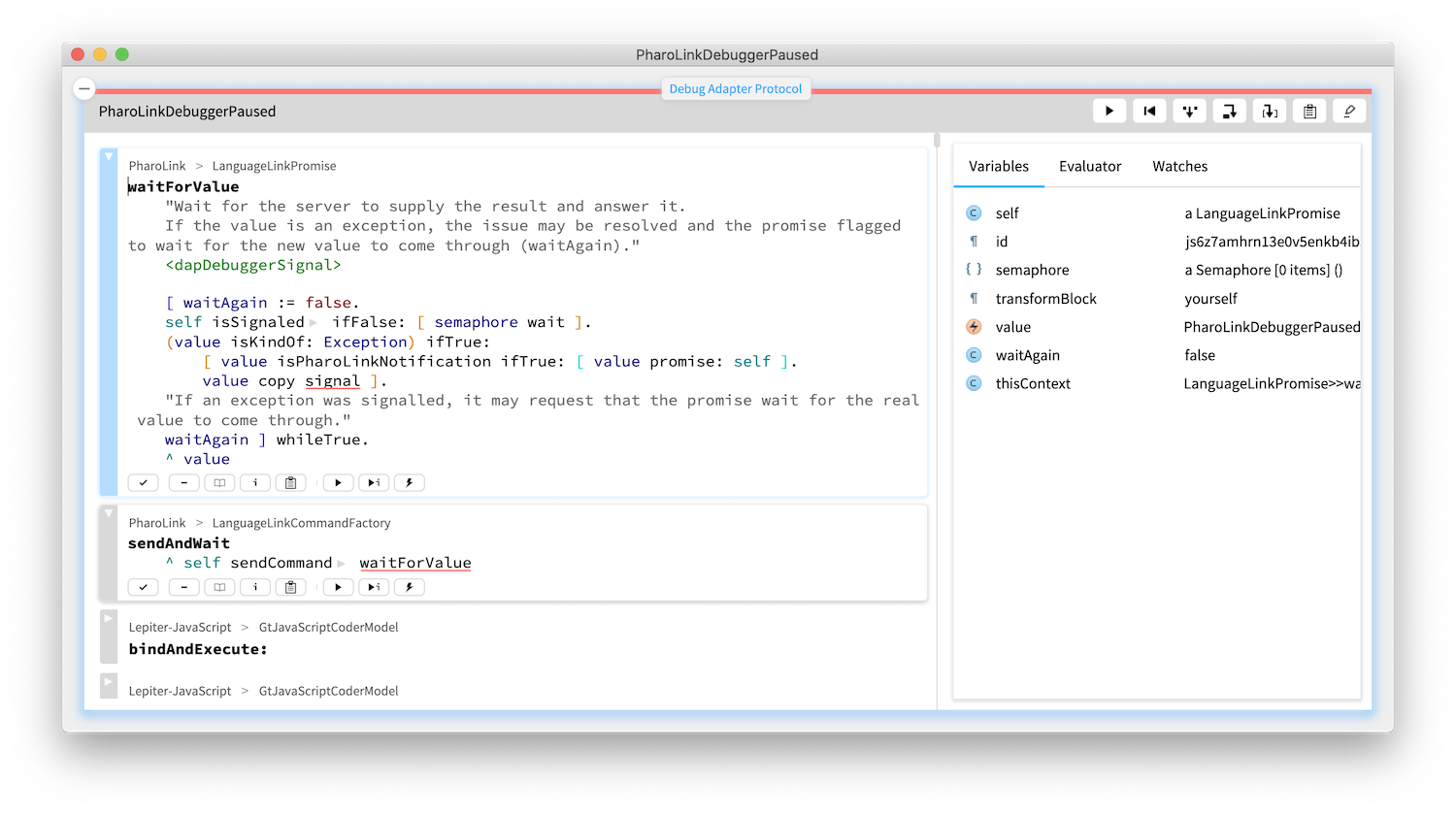
The integration of external runtimes also includes debugging abilities. Here is an example of a debugger opened by a breakpoint set in a JavaScript code. In other words, we get debuggable notebooks.
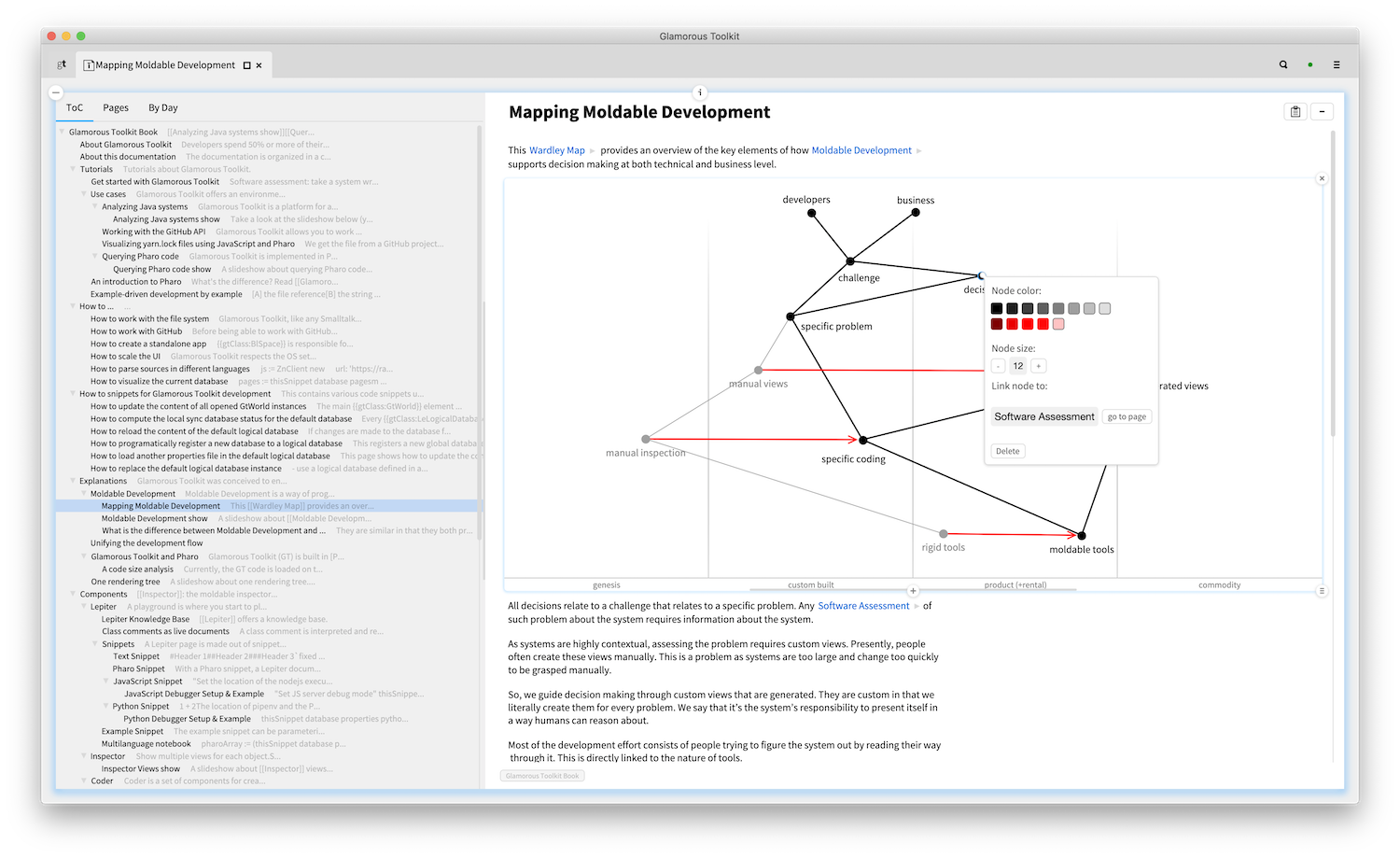
Snippets are not confined to textual representations either. Here is an example of a Wardley Map edited right in a page.
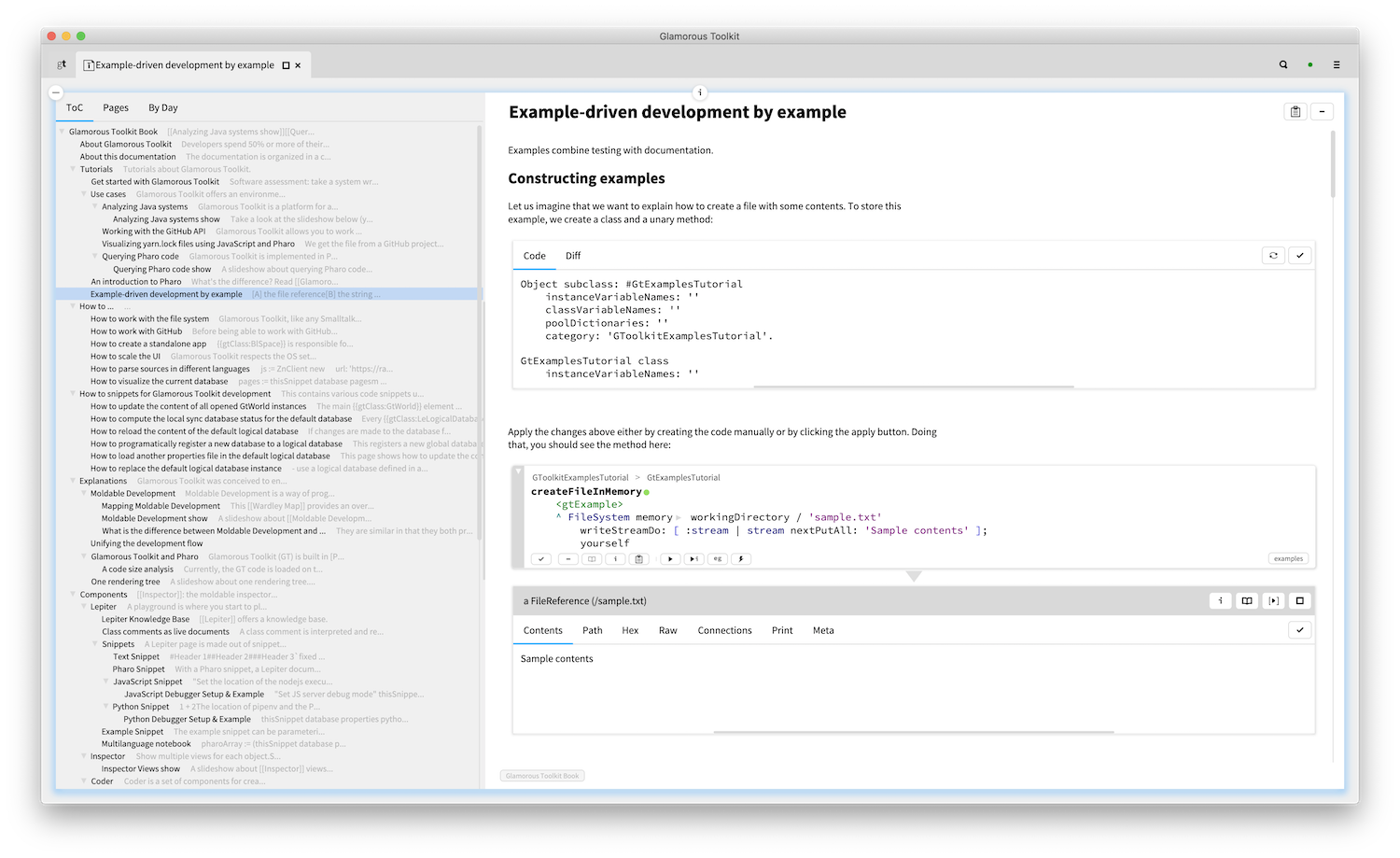
Other snippets are not necessarily languages per se, but definition of links for external content to be embedded. For example, here we see a page from a tutorial that shows a snippet specifying changes that can be applied to the system and an example snippet whose result can be previewed.
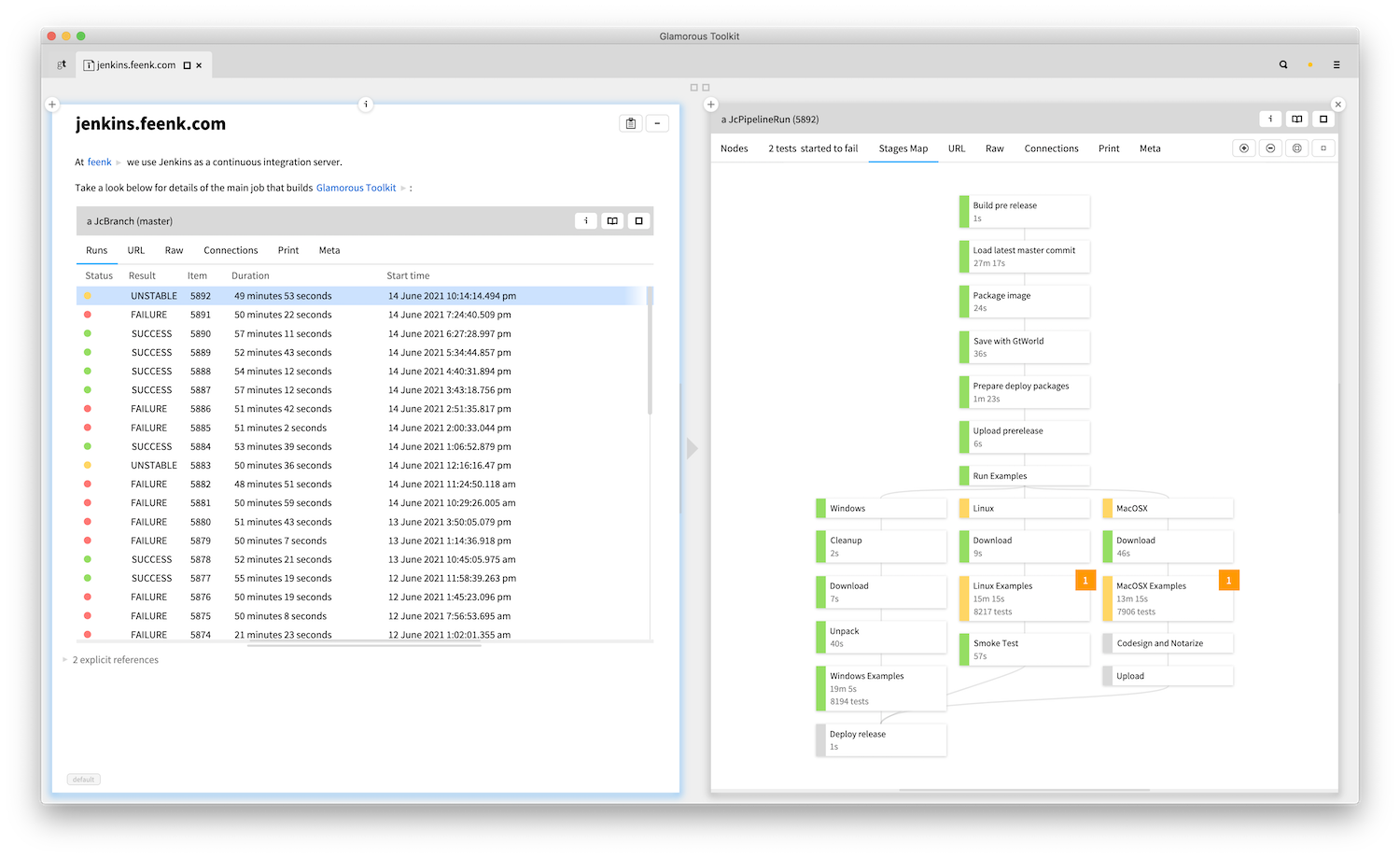
Yet other snippets work with external systems. Like an example of embedding the results of a Jenkins build extended by the ability of visualizing the deployment pipeline. This is also an example of how the system can be used for documenting and browsing APIs.
All links are bidirectional, as one would expect from a knowledge management system. And of course, you can see the references to a page.
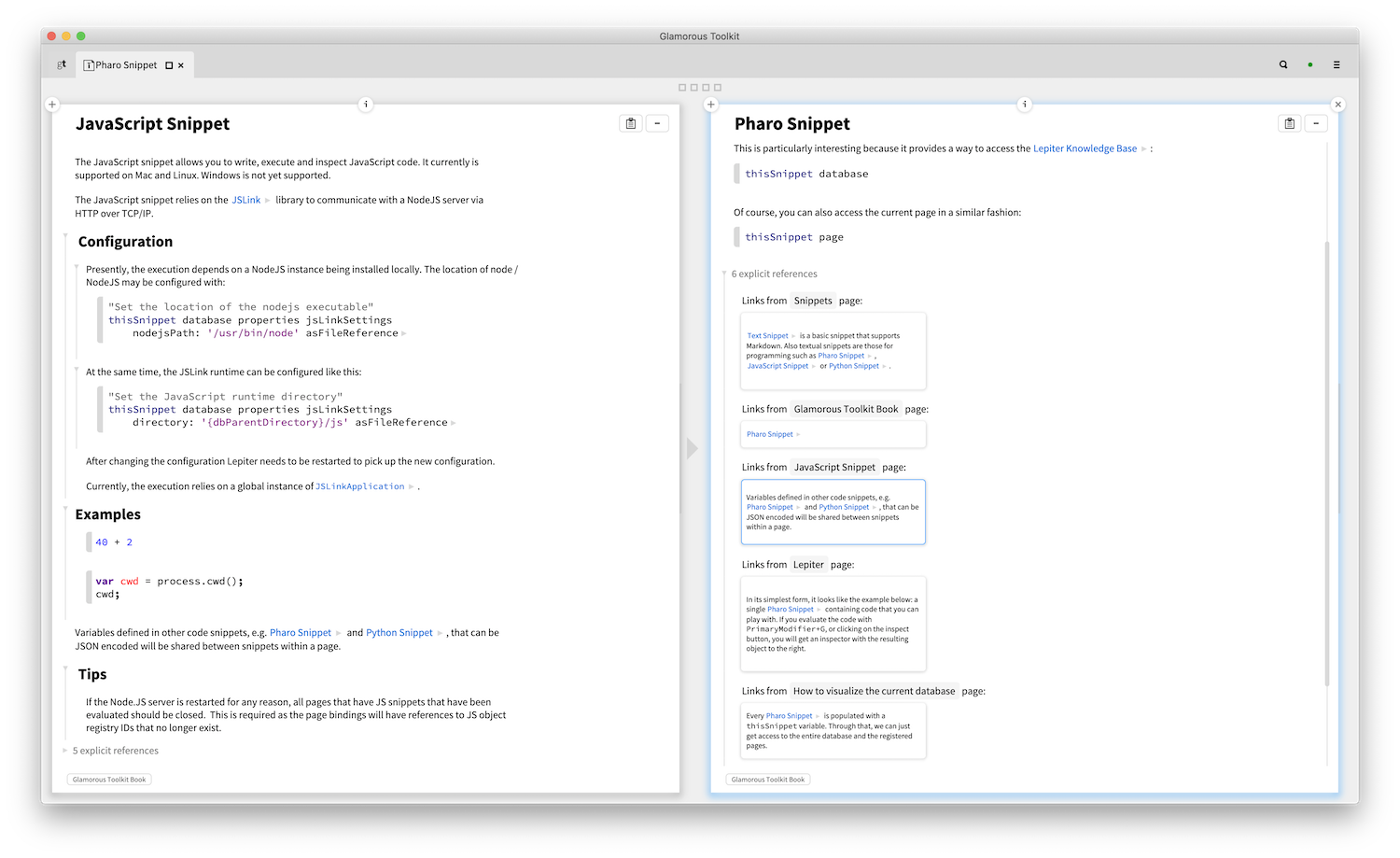
But, that's not quite all. A link can come from anywhere, including from inside a non-textual snippet. For example, we see here a Wardley Map referencing a page (entitled Software Assessment) only to see among the references of that page a nicely shown preview of the Wardley Map.
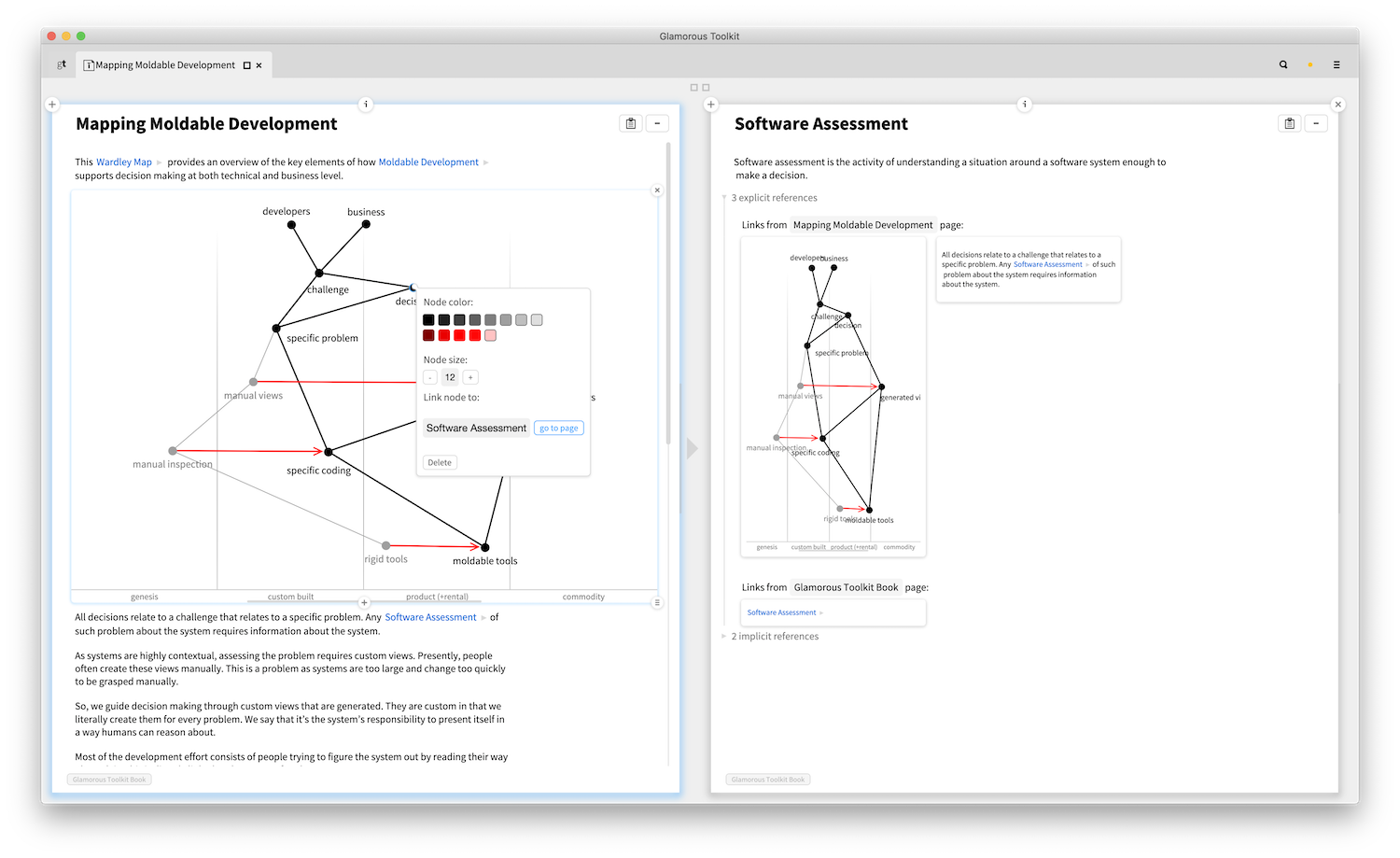
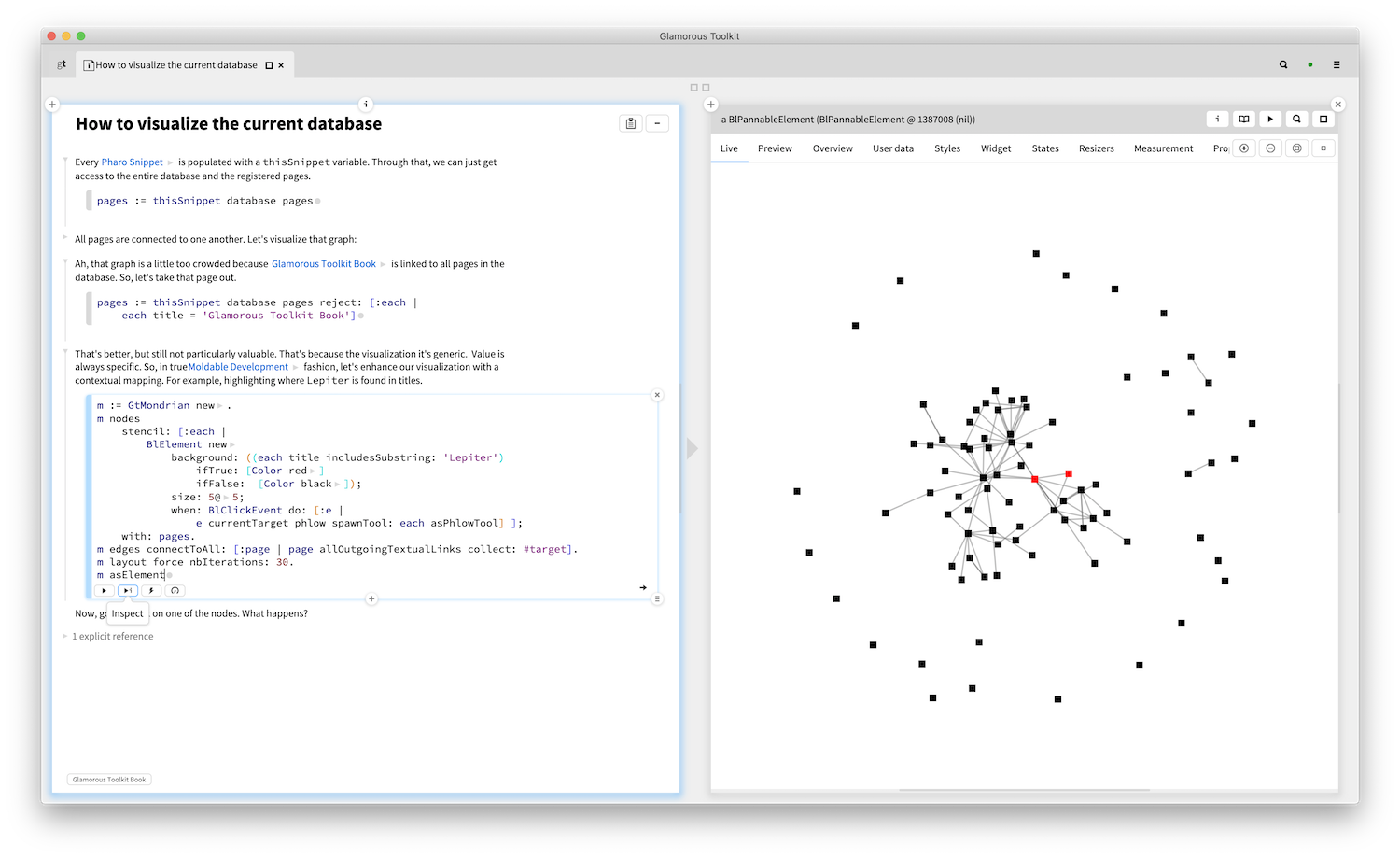
Talking about links, let's look at this example again: it shows a script that takes the current page database and visualizes the connections among pages while highlighting the pages that match a custom query.
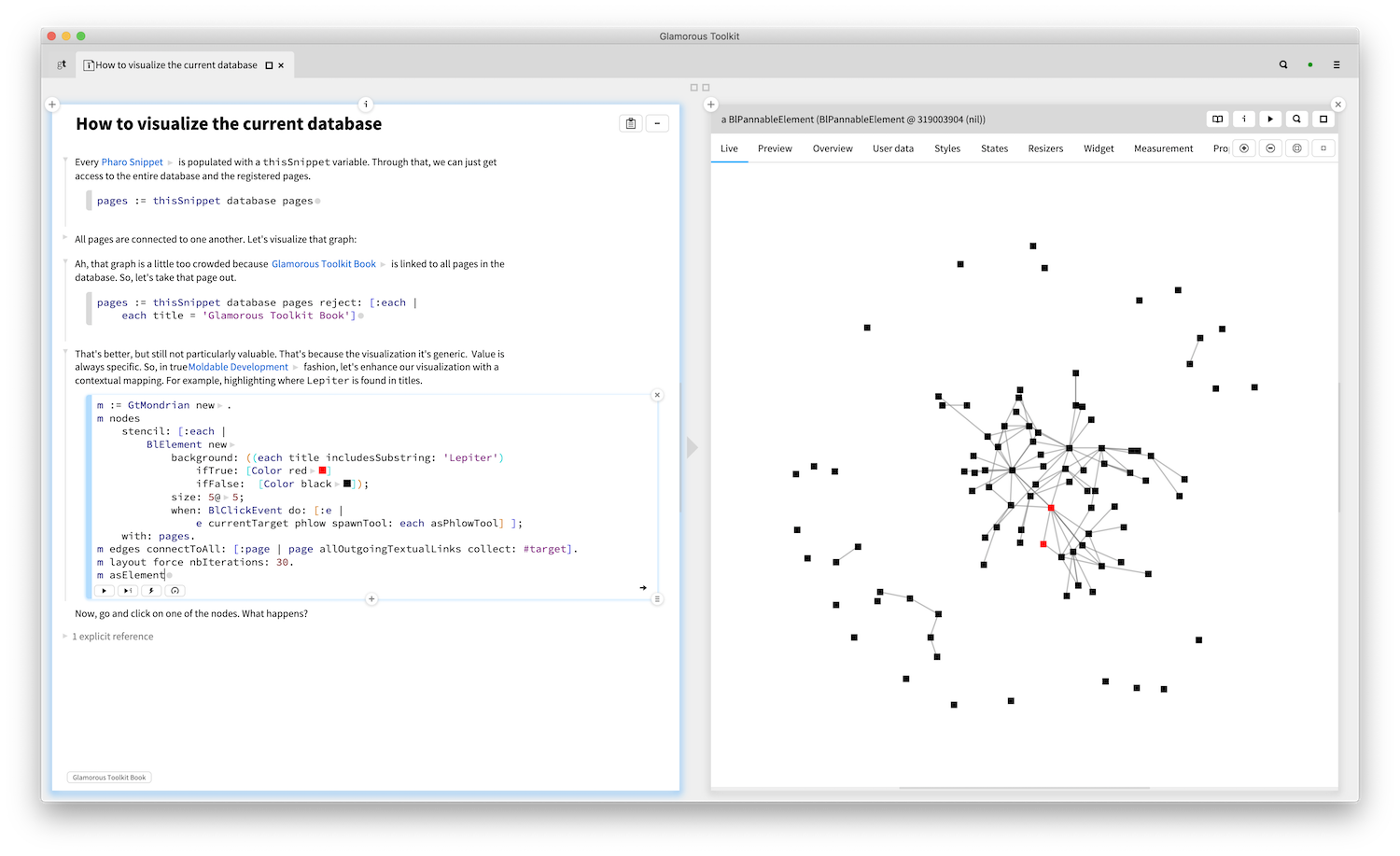
But, wait, there is a little more. Clicking on a node in the visualization spawns an editor on the page. Even though the visualization is hand crafted, it is an integral part of the environment and acts as a guide.
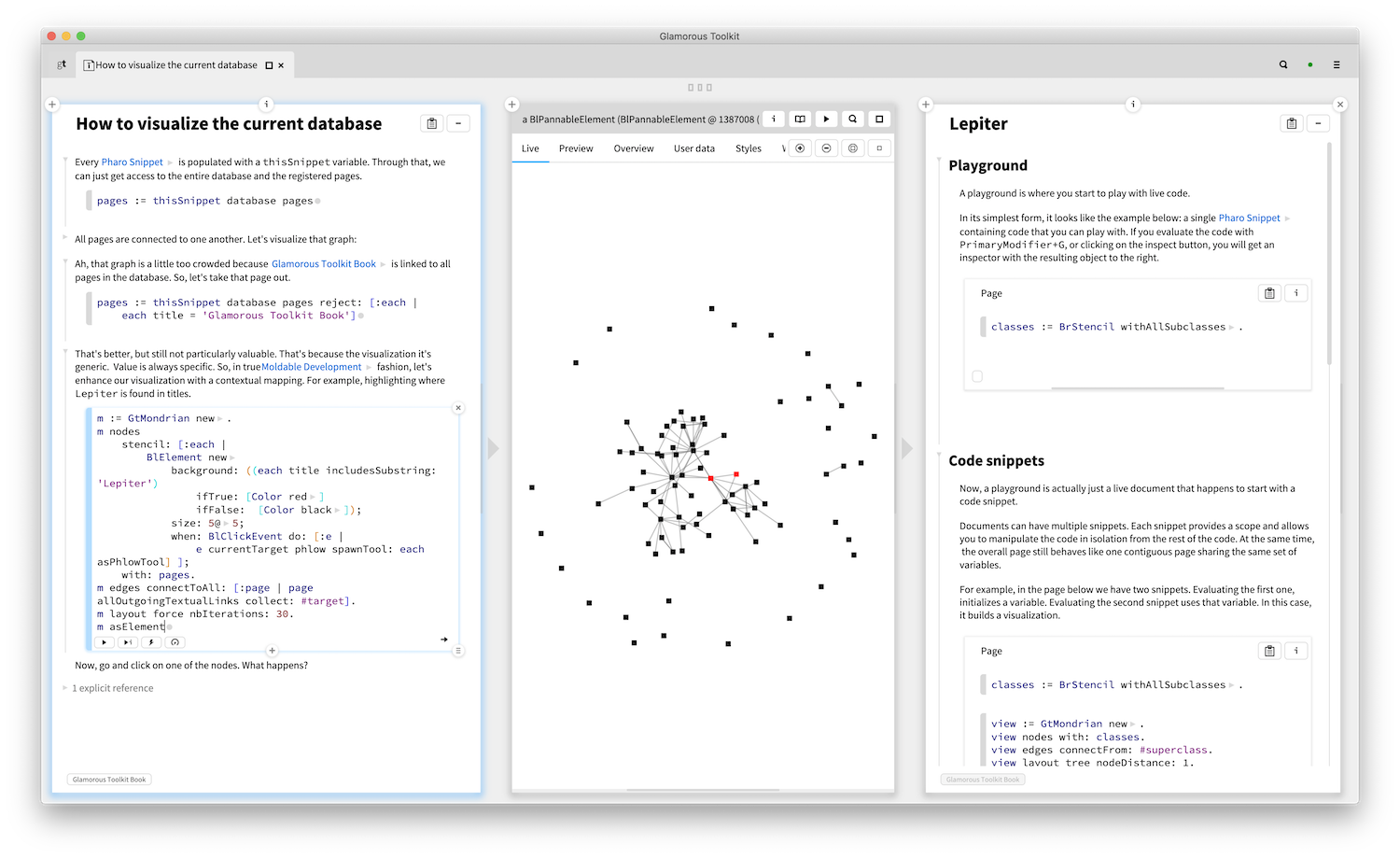
We talked about links and knowledge base. We should also say that there can be multiple knowledge bases, too. Each knowledge base is stored as structured text locally first. They can be versionned through Git, or synchronized through other mechanisms.
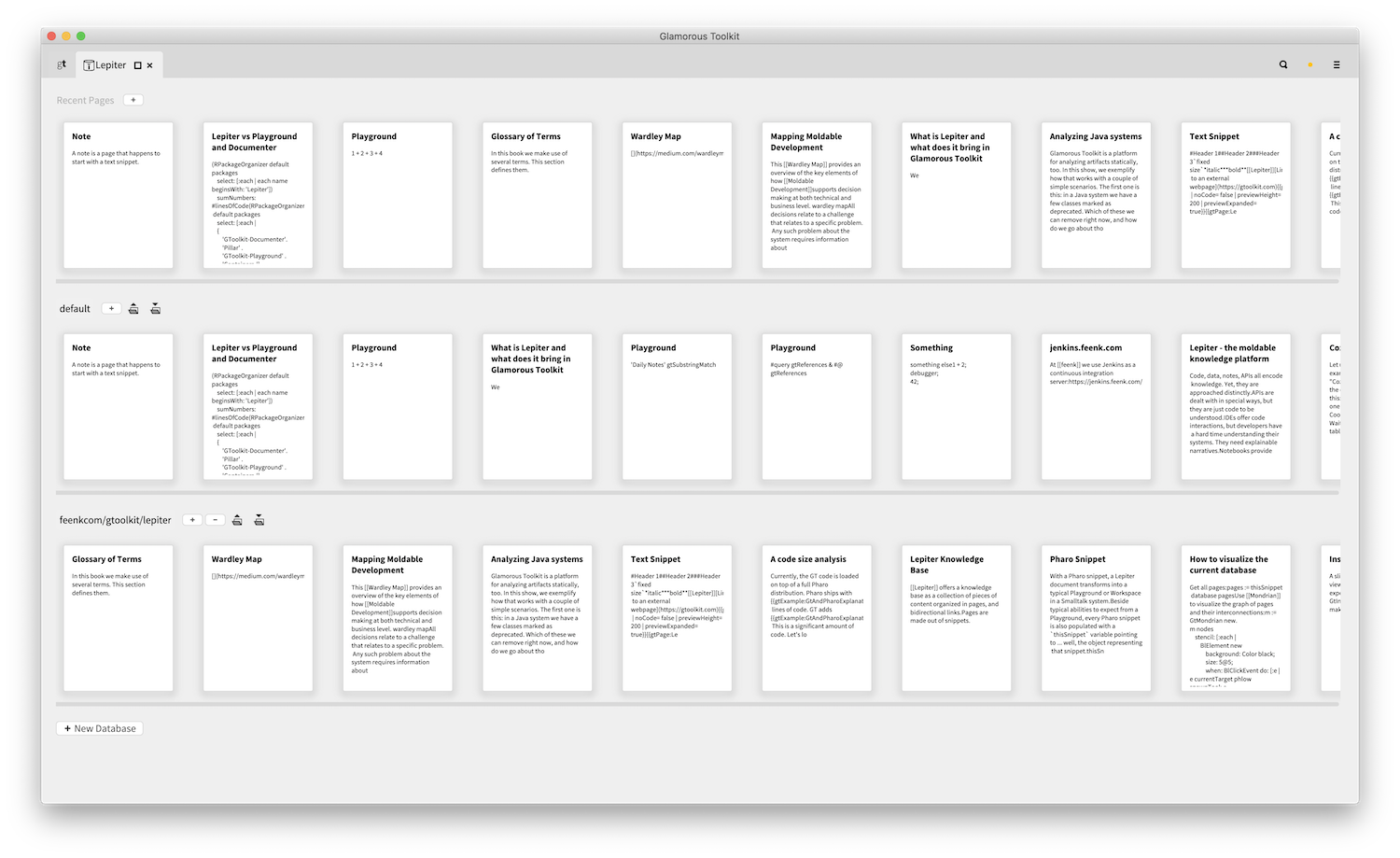
The open model is also paired with an infrastructure for import/export. By default, there are importers and exporters for RoamResearch databases and Jupyter notebooks. Yes, that's right. Exporters, too.
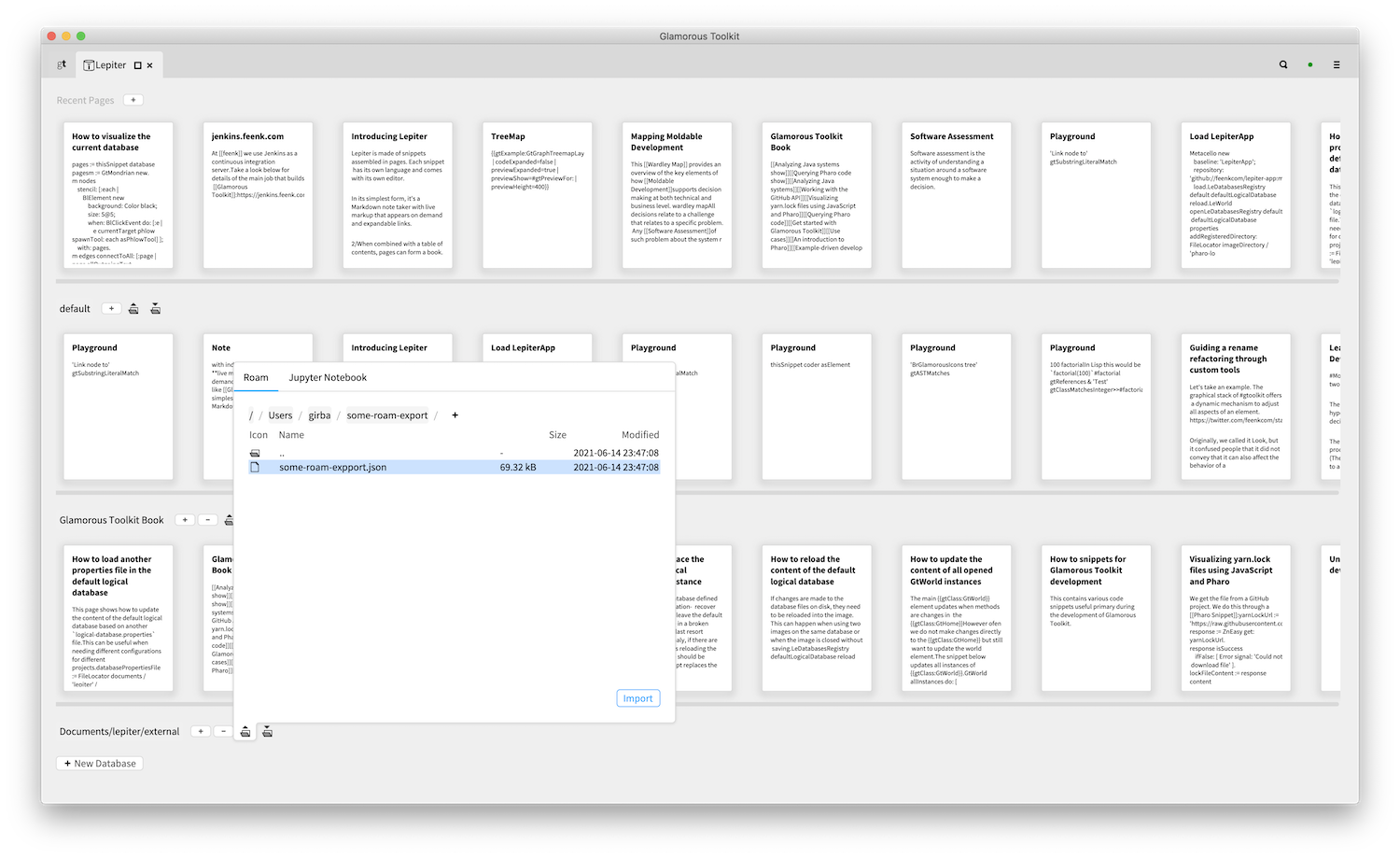
The whole system is extensible and programmable. Each page can be inspected in place and be programmed against.
Here we see an inspector in which we run a query against a page, find a snippet and view how that snippet is serialized.
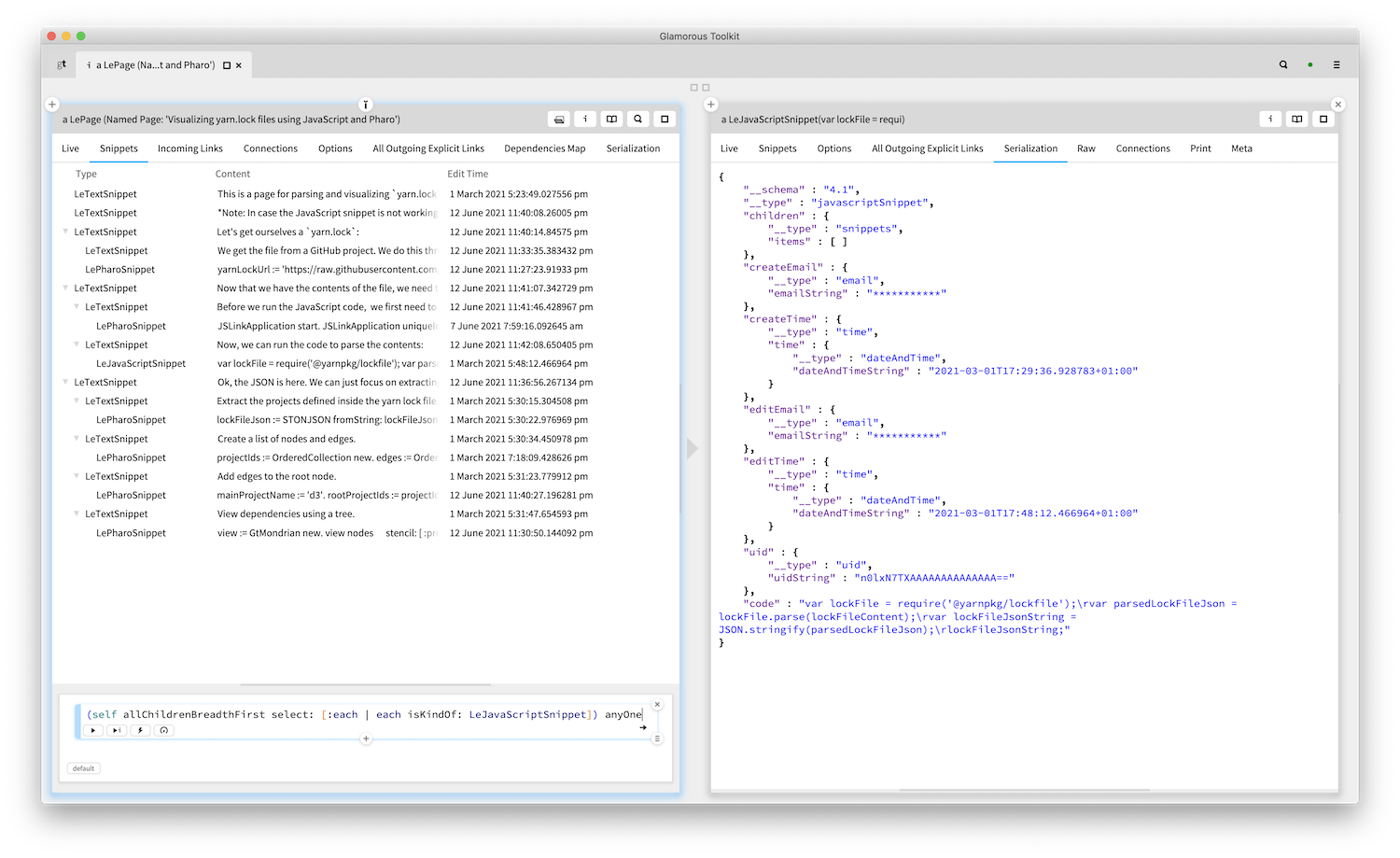
The extensibility goes deep: even the text snippet offers an extensible syntax. For example, in this snippet we parse a piece of text including custom annotations (gtClass and gtExample). These annotations are defined separately from the core Markdown parser, yet the result of parsing shows a a unified abstract syntax tree (Yes, we can debug the parser from inside the system, too). This is particularly interesting because we can define a uniform editing experience for custom extensions.
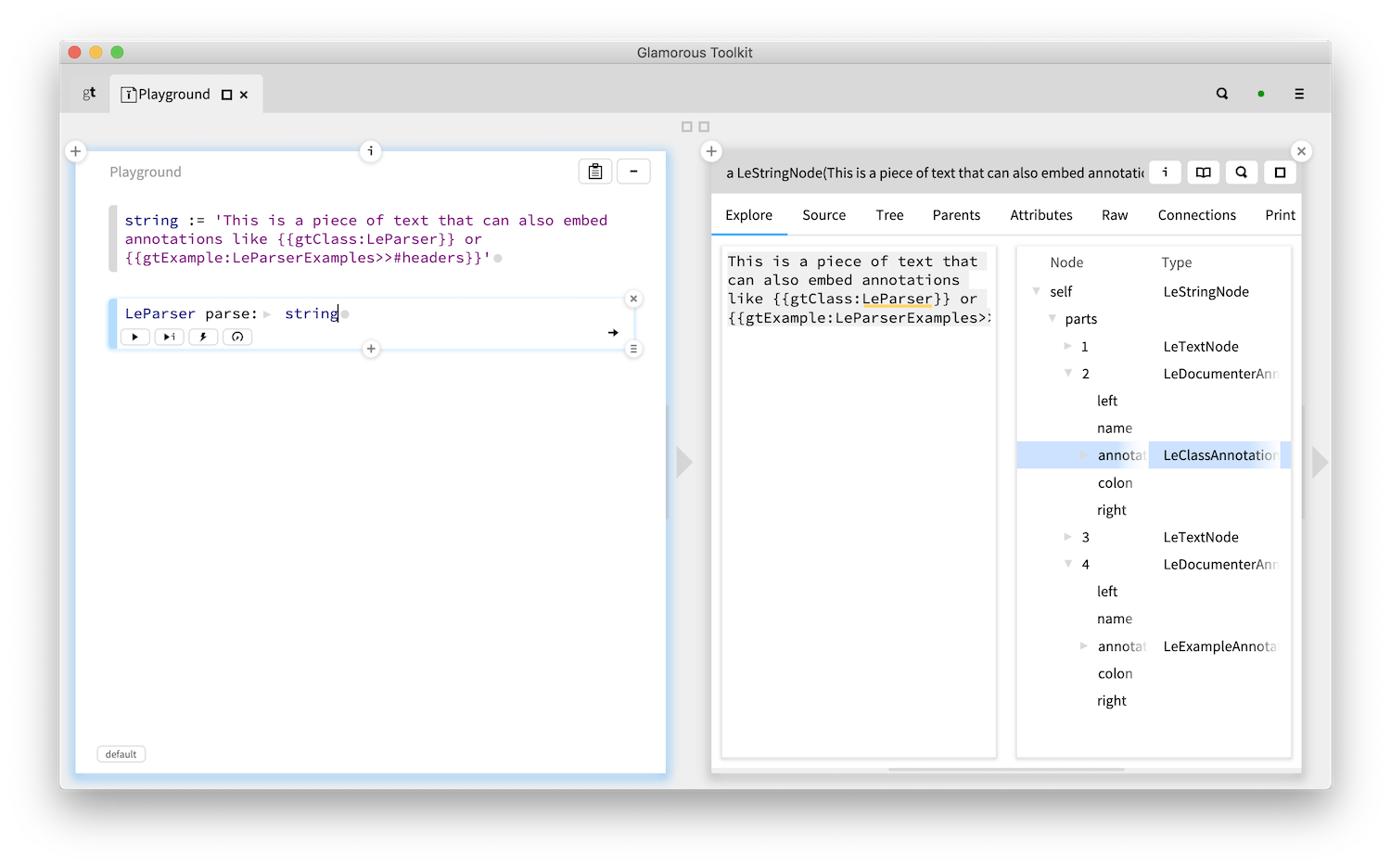
This combination between a live development environment and a knowledge management system empowers developers to create their own extensions and snippets and adapt to the technical and business context.
Why is Lepiter relevant?
That looks like a long list of abilities that Lepiter brings to the table. But, what we can list today is almost secondary. In our view, it is much more important that we could produce a deep integration that works seamlessly with the rest of the environment.
Take visualizing the knowledge graph. This alone can be touted as a feature of the environment. Only, in our case, it's nothing special. Merely the result of combining a notebook with custom views.
Or consider the debugger for JavaScript or Python. This debugger is actually the normal moldable debugger that recognizes from the stack that it waits for value from a foreign process and offers an extra debugger for interacting with the said process.
(As a side note, we designed this debugger in 2014. At the time, we did not know how it will work with accommodating other runtimes, but we thought it should. Well, it turns out it does work.)
The central idea of moldable development is that context comes first and tools should follow. There are many more contexts than we can predict and accommodate out of the box. The only way to handle contextual needs effectively is through programmability. First, every page is inspectable and directly programmable against. Second, every snippet is potentially an extensibility point. Third, even the language of the Markdown snippets are themselves extensible with new annotations. All these invite you to customize the experience to what is important in your context.
So, why is Lepiter relevant? Because it provides a unified starting point for all work. Jotting down a thought? Prototyping something? Documenting a system? Playing with data? Writing a multilanguage analysis?
Just start Lepiter.